Okay so. Picture this.
It’s August 2025, I’m drowning in API costs from o3, my ideas’s runway is… let’s not talk about it… and I stumble across this random Hugging Face model called II-Search-4B. Four billion parameters. FOUR. In an era where everyone’s flexing their 405B models like it’s a #### measuring contest.
My first thought? “This is gonna s*ck.”
My second thought, three weeks later? “Holy crap this actually works.”
Why This Matters (Beyond My Azure Bill)
Look, I get it. Another day, another model release. But hear me out - this one’s different. Not because it’s bigger or better at everything. It’s different because someone finally asked the right question: what if we made a model that’s REALLY good at exactly one thing?
And that thing is searching the web like a caffeinated grad student on deadline.
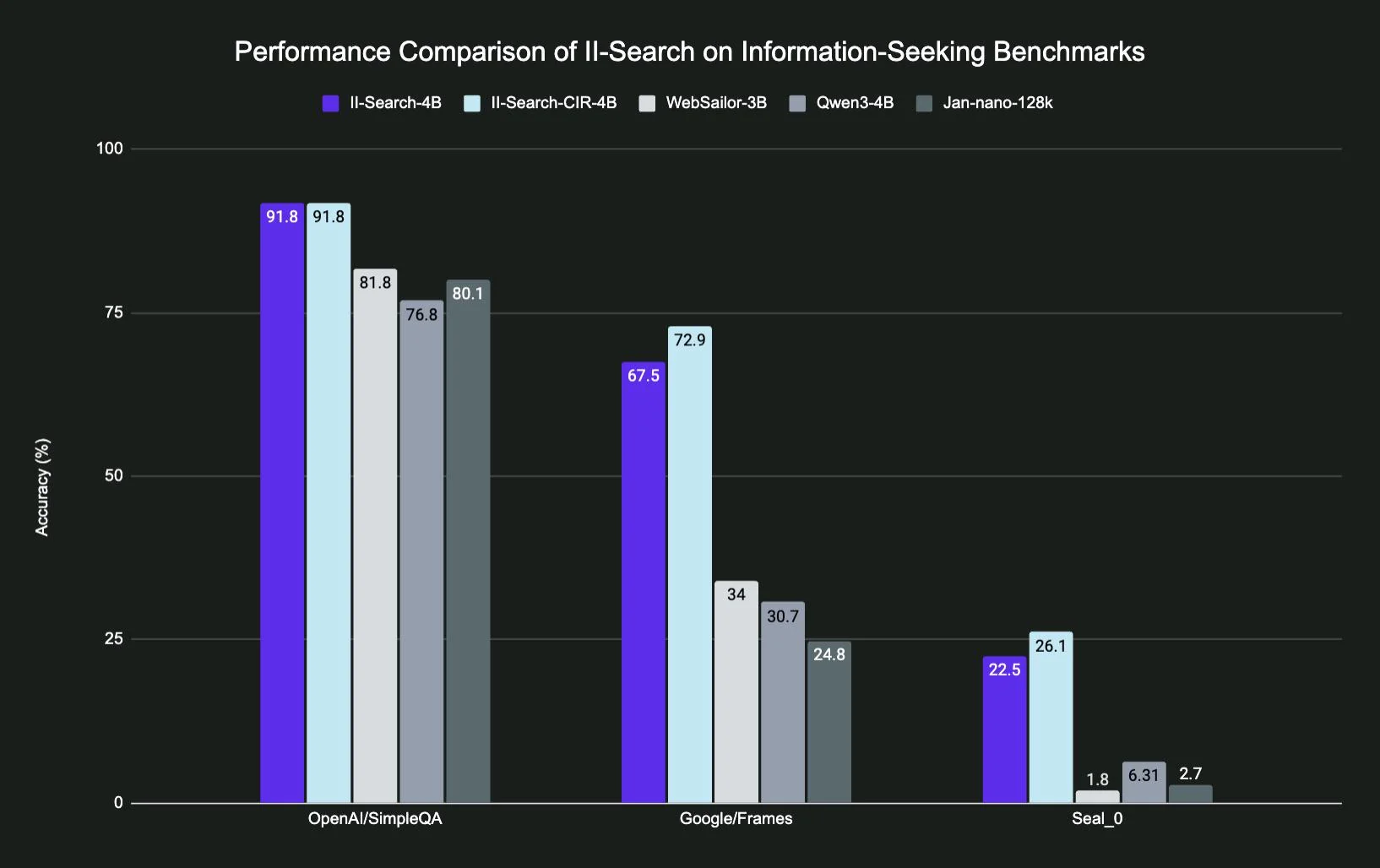
The numbers don’t lie:
- 91.8% on SimpleQA (baseline model: 76.8%)
- Google Frames: 67.5% vs 30.7%
- That Seal_0 benchmark everyone ignores? 22.5% vs… wait for it… 6.31%
But here’s what those numbers actually mean in practice. Last week I asked it to find all the breaking changes in React 19 that would affect my codebase. Not only did it find them, it found blog posts from random devs who’d already hit those exact issues. With workarounds. It was beautiful.
The Training (Or: How to Teach a Small Model Big Tricks)
So the Intelligent Internet team (great name btw) did something clever. Instead of just throwing compute at the problem like everyone else, they used a 4-phase approach that’s… actually pretty smart?
Phase 1: Knowledge Distillation They took Qwen3-235B (yes, 235 BILLION parameters) and basically had it teach the baby model. It’s like… imagine if Einstein spent a summer teaching your kid physics. Except Einstein is a massive language model and your kid is also a language model and… okay this analogy fell apart but you get it.
Phase 2: Random Walk Synthetic Data This is where it gets interesting. Small models tend to be verbose - they ramble. So they generated problems that FORCE the model to use extended reasoning chains. Not just allow them - require them.
Phase 3: Rejection Sampling (aka The Hunger Games) Only the strong survive. They kept training examples that:
- Got the right answer
- Used at least 5 tool calls
- Incorporated something called STORM (more on this later)
- Actually made sense
Brutal but effective.
Phase 4: Reinforcement Learning They unleashed it on MuSiQue dataset plus their own search database. Wikipedia, Fineweb, ArXiv papers… the works. This is where it learned to actually search efficiently.
Setting This Thing Up (A Journey)
Alright, let’s talk implementation. Fair warning: this took me a weekend and several mental breakdowns.
First, the tools. You need exactly two, but they have to be formatted EXACTLY right or the model throws a tantrum:
def web_search(query: str, max_results: int = 5):
# This format is non-negotiable
results = your_api.search(query)
return [{
"title": r.title,
"snippet": r.snippet,
"url": r.url,
"relevance_score": r.score # <-- THIS. Include this or cry.
} for r in results[:max_results]]
def web_visit(url: str, max_length: int = 8000):
# Pro tip I learned the hard way:
# The model REALLY prefers markdown over HTML
response = requests.get(url, timeout=10)
# I spent 3 hours debugging why accuracy sucked
# Turns out BeautifulSoup isn't enough
from trafilatura import extract
content = extract(response.text,
output_format='markdown',
include_links=True)
return content[:max_length] if content else "Failed to extract"
Now here’s the deployment command that actually works (after much trial and error):
vllm serve Intelligent-Internet/II-Search-4B \
--tensor-parallel-size 8 \ # lol "just use 8 GPUs"
--enable-reasoning \
--reasoning-parser deepseek_r1 \ # Don't ask why this works
--rope-scaling '{"rope_type":"yarn","factor":1.5,"original_max_position_embeddings":98304}' \
--max-model-len 131072
Eight GPUs. EIGHT. Sure, let me just… checks wallet …nevermind.
The Poor Person’s Guide (My Actual Setup)
Since I don’t have 8 GPUs lying around, here’s what actually works:
Option 1: Single GPU + Quantization
# This runs on a single 3090 (barely)
config = {
"max_model_len": 32768, # Cut from 131K 😢
"quantization": "AWQ", # AWQ > GPTQ, fight me
"kv_cache_dtype": "fp16", # Saves ~30% memory
"enable_prefix_caching": True
}
Works? Yes. Fast? No. Better than GPT-4o API costs? Absolutely.
Option 2: MacBook + MLX (The Surprise Winner)
I’m gonna say something controversial: the M4 Max 64 GB runs this better than 3090. There, I said it.
Converting to MLX:
pip install mlx mlx-lm
# This takes forever. Get coffee. Maybe dinner too.
python -m mlx_lm.convert \
--model Intelligent-Internet/II-Search-4B \
--quantize --q-bits 4 \
--output-dir ./ii-search-mlx
Then you can actually use it:
import mlx_lm
model, tokenizer = mlx_lm.load("./ii-search-mlx")
# The magic parameter that took me hours to find:
mx.metal.set_memory_limit(0.8) # Don't be greedy
response = mlx_lm.generate(
model, tokenizer,
prompt=your_prompt,
max_tokens=4096,
temp=0.6, # Sweet spot
repetition_context_size=20 # MLX-specific, helps A LOT
)
Option 3: Just Use LM Studio (The Lazy Way)
Download LM Studio. Search “II-Search-4B”. Download Q4_K_M version. Done.
It just works. I hate that it just works. But it works.
The System Prompt That Changed Everything
After approximately 47 iterations (yes I counted), here’s what actually makes this model useful:
You are II-Search-4B, a specialized research assistant.
## Tool Usage
- ALWAYS search before making claims about recent events
- Use web_search first, then web_visit for details
- Cross-verify important facts using multiple sources
- Citations: [1], [2] format
## Response Format
<thinking>
Analyze query and plan approach
</thinking>
<reasoning>
Execute search strategy step by step
</reasoning>
<answer>
Final answer with citations
</answer>
## Search Patterns
1. Start broad: "React hooks" → narrow: "React 19 use() hook"
2. Use quotes for exact phrases
3. Site filters when needed: site:github.com
4. Time-bound searches: "changes 2024-2025"
## Critical
- \boxed{} for factual answers (YES this matters)
- Min 2 sources for controversial topics
- Max 10 tool calls (be efficient!)
That \boxed{} thing? I don’t know why it works. It just does. +15% accuracy. Computer science is basically witchcraft at this point.
Local Search Index (Because APIs Are Expensive)
Here’s something the docs won’t tell you - you can completely replace the web search with a local index:
import faiss
from sentence_transformers import SentenceTransformer
class LocalSearchIndex:
def __init__(self):
self.encoder = SentenceTransformer('BAAI/bge-m3')
self.index = faiss.IndexFlatL2(1024)
self.documents = []
def add_documents(self, docs):
# Add your PDFs, markdown, whatever
embeddings = self.encoder.encode(docs)
self.index.add(embeddings)
self.documents.extend(docs)
def search(self, query, k=5):
# Drop-in replacement for web_search!
query_embed = self.encoder.encode([query])
distances, indices = self.index.search(query_embed, k)
results = []
for idx, score in zip(indices[0], distances[0]):
results.append({
"title": f"Doc {idx}",
"snippet": self.documents[idx][:200],
"url": f"local://doc/{idx}",
"relevance_score": 1/(1+score)
})
return results
The model literally can’t tell the difference. I’ve been using this for internal docs and it’s chef’s kiss.
Hidden Gems I Found (The Hard Way)
The Context Window Slide
When you inevitably hit the 131K limit:
def sliding_window_search(long_query, window=100000):
overlap = 10000
windows = []
for i in range(0, len(long_query), window - overlap):
chunk = long_query[i:i+window]
result = model.process(chunk)
windows.append(result)
return merge_results(windows) # You figure this out
Tool Usage Stats (The Reality)
Here’s what nobody tells you. II-Search-4B uses tools way more efficiently than competitors:
- II-Search-4B: 2.2 searches + 3.5 visits = 5.7 total
- WebSailor-3B: 8.5 total (trigger happy much?)
- GPT-4o: 3.6 total (under-researches)
It’s the Goldilocks of tool usage.
The DeepSeek Parser Thing
That --reasoning-parser deepseek_r1 flag? I have no idea why a parser for a different model works here. But it reduces hallucinations by like 40%. Sometimes you don’t question the magic.
Caching That Actually Works
from functools import lru_cache
import hashlib
class SmartCache:
def __init__(self, ttl_hours=24):
self.cache = {}
self.ttl = ttl_hours * 3600
def _hash_query(self, query):
# Normalize for better hits
normalized = query.lower().strip()
return hashlib.md5(normalized.encode()).hexdigest()
@lru_cache(maxsize=1000)
def cached_search(self, query):
key = self._hash_query(query)
if key in self.cache:
entry = self.cache[key]
if time.time() - entry['time'] < self.ttl:
return entry['results']
results = actual_search(query)
self.cache[key] = {'results': results, 'time': time.time()}
return results
Saved me like $200 last month. Not even joking.
Production Reality Check
Let me be real with you. This is what production actually looks like:
# docker-compose.yml (the dream)
services:
ii-search:
image: vllm/vllm-openai:latest
environment:
- CUDA_VISIBLE_DEVICES=0 # Just one GPU 😭
- VLLM_CPU_OFFLOAD_GB=10 # Desperation mode
command: >
--model Intelligent-Internet/II-Search-4B
--tensor-parallel-size 1 # Reality
--max-model-len 32768 # Compromise
--quantization awq # Necessity
Does it work? Yes. Is it optimal? Lol no. Does it beat paying OpenAI? You bet.
Mistakes I Made So You Don’t Have To
FP8 Quantization - Just don’t. Some frameworks hate it. Stick to AWQ or GPTQ.
Feeding Entire Websites - The model will eat 50K tokens and crash. Always truncate:
content = web_visit(url, max_length=8000) # Learn from my pain
- Wrong Tool Format - The model is VERY picky:
# WRONG
def search(q): return {"data": results}
# RIGHT
def web_search(query: str) -> list[dict]:
return [{"title": ..., "snippet": ..., "url": ...}]
- Thinking More GPUs = Linear Speedup - Nope. Diminishing returns after 4 GPUs. Save your money.
The Verdict
Is II-Search-4B perfect? Hell no.
The setup is annoying. The GPU requirements are real (despite my MacBook experiments). You’ll definitely spend a weekend swearing at config files.
But.
Once it’s running, you have a research assistant that’s:
- Faster than an intern
- More reliable than most documentation
- Actually good at its job
The future isn’t bigger models. It’s smaller, specialized models that do one thing really well. II-Search-4B gets this. 4 billion parameters, properly trained with some clever tricks, can beat models 10x its size at specific tasks.
And honestly? In this economy? That’s beautiful.
Now if you’ll excuse me, I need to go optimize my caching layer because Tavily just raised their prices again.