Reading time: ~45 min | Audience: platform leads, principal engineers, AI architects, security teams | Primary goal: build agent systems that stay stable under real enterprise pressure
Preface: Why I Wrote This Version
Quick context on why this exists.
I have read too many agent posts that sound convincing and then collapse in real enterprise environments. Usually they miss one of three things:
- They stop at demos.
- They show code without operations.
- They draw architecture without incident behavior.
This version is for teams that already shipped something and now need clear answers in design review, security review, and on-call:
- What if a privileged tool call is wrong?
- What is our safe resume path at step 14 of 20?
- Can we prove controls without hand-waving?
- Why did cost jump this week while quality stayed flat?
If those are your questions, this playbook is for you.
Reality Check: Where Microsoft Agent Framework Stands (March 1, 2026)
There is enough public signal to treat MAF as a serious enterprise candidate, but not enough to skip disciplined release hygiene.
- Microsoft announced Release Candidate on February 19, 2026. S1
- Core Learn docs for workflows, middleware, observability, approvals, and checkpoints were refreshed in February 2026 windows.
- Workflow framework guidance explicitly documents orchestration options (sequential, concurrent, handoff, and group-chat style patterns) and workflow concepts such as supersteps and event-driven execution.
- The Workflows overview page itself shows a last updated stamp on February 13, 2026, which is useful for release-readiness discussions with stakeholders. S2 S5 S6 S7 S8 S10
My practical read for enterprise teams:
- Treat APIs as stable enough for controlled production pilots.
- Pin versions and test upgrades with replay/restore, not just unit tests.
- Keep framework upgrades and business logic changes in separate release trains.
What This Playbook Covers (and What It Does Not)
It covers
- Decision frameworks for orchestration patterns.
- Policy design for privileged tools.
- Reliability design with checkpoint and restore.
- Observability patterns for debugging, safety, and economics.
- Rollout sequencing that works in enterprise organizations.
It does not cover
- Prompt engineering basics.
- Introductory LLM concepts.
- Generic “hello world” demos.
Those are easy to find and not where projects fail.
The Core Thesis
The hardest part of agent adoption in 2026 is not getting a model to produce good text. The hardest part is building a system where:
- Autonomy is bounded.
- Risk is explicit.
- Failures are recoverable.
- Operations are explainable.
If you cannot explain, in plain language, why a run took an action and how to safely resume from failure, your architecture is not production-ready yet.
1. Why “One Smart Agent” Breaks in Enterprise Workloads
Teams usually start the same way: one powerful agent, broad instructions, and many tools.
It works in demos.
Then real traffic hits, weird edge cases appear, and confidence drops fast.
Here is why, based on recurring implementation reviews:
Failure Pattern A: Policy-in-prompt architecture
Authorization and business controls are expressed as instructions instead of enforced controls. The system appears compliant until the first edge case.
Failure Pattern B: Unbounded execution
No hard limits for tool calls, turn count, or run duration. Cost and latency volatility follows.
Failure Pattern C: No resumability strategy
When a workflow fails at 80% progress, teams restart from zero. This is expensive and operationally painful.
Failure Pattern D: Missing causality in telemetry
You have logs, maybe traces, but not enough correlation to answer who/what/why during incidents.
The fix is not better prompting. The fix is decomposition plus explicit control planes.
There is a subtle point in the official overview that is easy to ignore and expensive to learn the hard way: Microsoft explicitly positions agents for nondeterministic tasks where dynamic planning is needed, and workflows for deterministic process control. If you ignore that split and put deterministic business rules into unconstrained agent loops, you usually pay for it later in reliability and auditability. S2
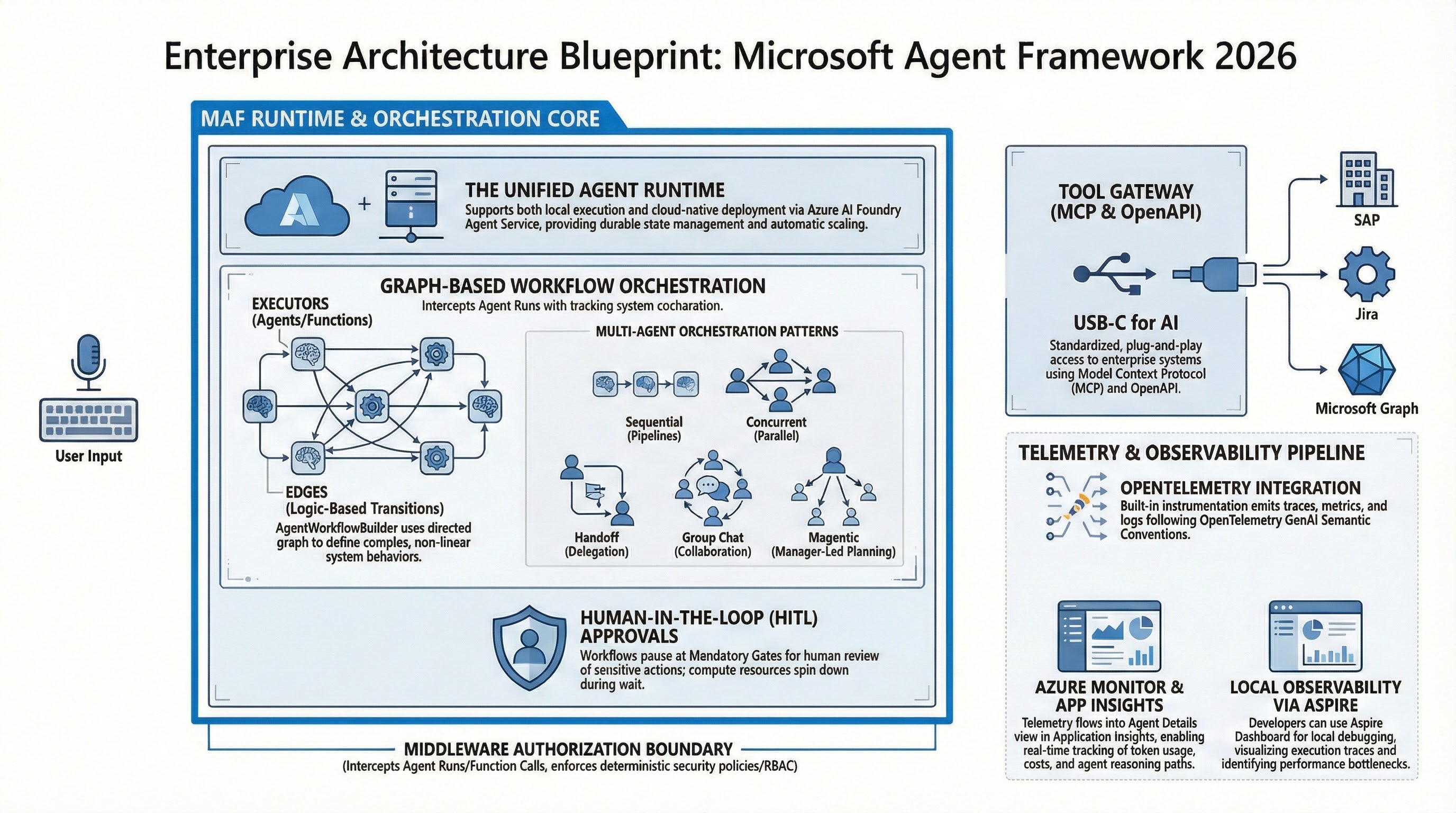
2. The Four-Plane Operating Model
flowchart LR
U[User or Channel] --> O[Workflow Orchestrator]
O --> M[Policy Middleware]
M --> A[Agent Executor]
A --> T[Tool Layer]
T --> X[MCP Servers, APIs, Data Stores]
M --> G[Approval Guard]
G --> H[Human Reviewer]
A --> C[Checkpoint Storage]
A --> E[OpenTelemetry Export]
E --> D[SLO Dashboards and Alerts]
C --> R[Restore and Replay]| Plane | Primary Question | Owner | Production Artifact |
|---|---|---|---|
| Orchestration | What should happen next? | platform engineering | workflow graph + budgets |
| Policy | What is allowed to happen? | security/platform | middleware policy + tool classes |
| Reliability | What if execution fails now? | SRE/platform | checkpoint + restore drill evidence |
| Observability | Can we explain this run quickly? | SRE/data | traces/events/SLO dashboards |
This model maps well to Azure orchestration guidance and, more importantly, keeps runtime governance out of prompt text where it does not belong. S9 S10
2.1 Why this model changes team behavior
Without this split, one team owns everything and tradeoffs stay implicit. With this split:
- Platform owns orchestration contracts and runtime budgets.
- Security owns policy classes and approval boundaries.
- SRE owns recoverability and observability quality gates.
- Product owns value metrics and business acceptance criteria.
That point matters most during incidents, when clear ownership cuts debate time and speeds recovery.
2.2 Workflow framework concepts to put in your ADRs
When teams skip formal architecture decision records (ADRs) for workflow semantics, they end up with vague runbook language and ambiguous failure handling. At minimum, document:
- Superstep boundaries: where checkpoints can be safely resumed.
- Event model: which events are emitted, stored, and used for alerting.
- State ownership: which node owns which fields and mutation rights.
- Termination conditions: max turns, completion events, and timeout exits.
These concepts are directly reflected in framework docs and should not be treated as implementation trivia. They are your operational contract. S10 S8
3. Pattern Selection: Choose Your Complexity Budget
Pattern choice is where many teams accidentally create future instability.
| Pattern | Start Here If | Hidden Cost | When to Upgrade |
|---|---|---|---|
| Sequential | process steps are known and ordered | can under-utilize parallelism | when independent branches emerge |
| Concurrent | independent steps can run safely | conflict resolution becomes necessary | when latency needs force parallelism |
| Handoff | specialist routing adds clear value | routing drift and loops | when taxonomy and router quality are mature |
| Group-chat / Magentic | task is exploratory or adversarial | hard governance and cost predictability | only for bounded high-value domains |
Two heuristics I use in design reviews:
- If stakeholders ask for auditability first, start sequential.
- If stakeholders ask for adaptability first, demand stronger guardrails before dynamic patterns.
3.1 Pattern selection checklist (what to decide before coding)
Before implementing any workflow graph, answer these questions in writing:
- Is this workflow mostly deterministic or mostly adaptive?
- Which steps can run in parallel without shared-state conflicts?
- Which actions create side effects and therefore require approvals?
- What is the acceptable blast radius for a wrong decision?
- What are the stop conditions when model quality drops mid-run?
If these are unanswered, architecture discussions are premature; you are still in requirement discovery.
4. A Concrete 14-Day Pilot Plan
This plan is strict on purpose. Loose pilots create misleading confidence.
Days 1-2: Define one workflow contract
- One business objective.
- One measurable quality metric.
- One owner who accepts or rejects output.
- One escalation path.
Days 3-4: Define runtime budgets
max_turnsmax_tool_callsmax_runtime_seconds- retry policy per step
These are not tuning suggestions. These are guardrails.
Days 5-6: Implement policy middleware
- Tool class allowlist.
- Role-based action permissions.
- Explicit approval requirements for privileged classes.
- A single shared middleware policy path for both streaming and non-streaming execution.
Days 7-8: Add approval UX and audit trail
- Reviewer sees enough context to decide safely.
- Reviewer identity and decision reason are logged.
- Rejected actions return useful fallback behavior.
Days 9-10: Instrument observability and economics
- Run-level trace spans.
- Step-level workflow events.
- Tool invocation telemetry.
- Cost per successful run.
Days 11-12: Add checkpoint and run failure drills
- Persist checkpoint at stable boundaries.
- Kill run intentionally.
- Restore from checkpoint and verify correctness.
- Verify side-effect idempotency for resumed steps.
Days 13-14: Red-team and release review
- Prompt injection tests.
- Tool misuse tests.
- Data leakage checks.
- Security + SRE + product sign-off.
If any of these fail, do not scale traffic yet.
5. Implementation Patterns (Problem -> Fix)
5.1 Baseline execution APIs: useful but not sufficient
# Non-streaming
result = await agent.run("What is the weather like in Amsterdam?")
print(result.text)
# Streaming
async for update in agent.run("What is the weather like in Amsterdam?", stream=True):
if update.text:
print(update.text, end="", flush=True)
// Non-streaming
Console.WriteLine(await agent.RunAsync("What is the weather like in Amsterdam?"));
// Streaming
await foreach (var update in agent.RunStreamingAsync("What is the weather like in Amsterdam?"))
{
Console.Write(update);
}
These APIs are your execution boundary, not your safety architecture. S11
5.2 Middleware boundary: where governance should live
Problem: controls are hidden in prompts and easy to bypass accidentally.
Fix: enforce policy in middleware.
async def policy_middleware(context: AgentContext, next: Callable[[AgentContext], Awaitable[None]]) -> None:
# Hard runtime controls
context.metadata["max_tool_calls"] = 6
context.metadata["max_turns"] = 12
context.metadata["max_runtime_seconds"] = 90
# Tool risk classes for downstream enforcement
context.metadata["approval_required"] = [
"payments.write",
"records.delete",
"external.notification.send",
]
await next(context)
var middlewareEnabledAgent = originalAgent
.AsBuilder()
.Use(runFunc: CustomAgentRunMiddleware, runStreamingFunc: CustomAgentRunStreamingMiddleware)
.Use(CustomFunctionCallingMiddleware)
.Build();
Operational nuance: test both streaming and non-streaming middleware chains. Teams often harden one path and forget the other. S5
Another nuance from the middleware docs: sharing one middleware function across run and streaming paths is fine, but behavior still differs under backpressure and partial-output timing. Keep shared logic, but run path-specific tests.
5.3 Human approval flows: practical design details
Problem: approvals exist, but reviewer context is too weak to decide correctly.
Fix: include action summary, target object, estimated impact, and rollback hint in approval payload.
@tool(approval_mode="always_require")
def update_finance_record(record_id: str, amount: float) -> str:
return f"Updated {record_id} to {amount}"
AIFunction paymentFunction = AIFunctionFactory.Create(ProcessPayment);
AIFunction approvalRequiredPaymentFunction = new ApprovalRequiredAIFunction(paymentFunction);
sequenceDiagram
participant U as User
participant A as Agent
participant G as Approval Guard
participant H as Human Reviewer
participant T as Privileged Tool
U->>A: Request task
A->>G: FunctionApprovalRequest
G->>H: Show action and context
alt Approved
H-->>G: Approve
G-->>A: ApprovalResponse(true)
A->>T: Execute tool call
T-->>A: Tool result
A-->>U: Final response
else Rejected
H-->>G: Reject
G-->>A: ApprovalResponse(false)
A-->>U: Denied or fallback response
endTwo implementation details tend to be missed:
- Approval loops are sessionful. Your approval response must be correlated with the right run/session state, not treated like a stateless callback.
- Rejection handling needs an explicit user-facing fallback path (for example, read-only summary or escalation), otherwise users experience it as a dead end.
5.4 Checkpoint strategy: recovery is a product feature
Problem: checkpoint API exists, but nobody validates restore semantics.
Fix: define checkpoint boundaries and test restore in release gates.
checkpoint_storage = InMemoryCheckpointStorage()
# ... build workflow with checkpoint storage ...
checkpoints = await checkpoint_storage.list_checkpoints()
saved_checkpoint = checkpoints[5]
async for event in workflow.run_stream(checkpoint_id=saved_checkpoint.checkpoint_id):
...
var checkpointManager = new CheckpointManager();
Checkpointed<StreamingRun> checkpointedRun = await InProcessExecution
.StreamAsync(workflow, input, checkpointManager)
.ConfigureAwait(false);
CheckpointInfo savedCheckpoint = checkpoints[5];
await checkpointedRun.RestoreCheckpointAsync(savedCheckpoint, CancellationToken.None).ConfigureAwait(false);
stateDiagram-v2
[*] --> Running
Running --> SuperStepDone: SuperStepCompletedEvent
SuperStepDone --> CheckpointSaved: persist CheckpointInfo
CheckpointSaved --> Running: continue execution
Running --> Failed: error, timeout, cancellation
Failed --> Restoring: select checkpoint
Restoring --> Running: restore and resume
Running --> Completed: WorkflowOutputEvent
Completed --> [*]Checkpoint design should include side-effect discipline. A restored run must not duplicate irreversible operations (for example payments, deletions, or outbound notifications). The practical pattern is:
- Persist idempotency keys with checkpoint metadata.
- Guard side-effect tools with dedupe checks.
- Record side-effect hashes in telemetry before completion acknowledgment.
Without this, restore correctness is mostly luck.
5.5 MCP integrations: never treat them like harmless plugins
async with (
MCPStdioTool(name="calculator", command="uvx", args=["mcp-server-calculator"]) as mcp_server,
Agent(chat_client=OpenAIChatClient(), name="MathAgent", instructions="You are a helpful math assistant.") as agent,
):
result = await agent.run("What is 15 * 23 + 45?", tools=mcp_server)
The operational risk is not the API call. The risk is hidden trust expansion.
Minimum controls I recommend for MCP:
- Endpoint inventory with owner and purpose.
- Network segmentation and egress restrictions.
- IAM scoping per server.
- Tool invocation logs with run IDs.
The broader MCP security model emphasizes user consent, tool safety boundaries, and explicit trust assumptions between host, client, and server. Treat that model as architecture input, not implementation detail. S14 S18 S19
6. Security and Governance Translation Layer
Security teams and application teams often use different language for the same risks. This table helps close that gap.
| Threat Theme | Engineering Control | Governance Evidence |
|---|---|---|
| prompt injection | context validation plus tool allowlist | blocked-action telemetry with reason code |
| excessive autonomy | approval-required tool classes | approval decision history with identity |
| sensitive data leakage | safe telemetry defaults | periodic data exposure audit |
| privilege escalation | least privilege credentials | scope matrix and review approvals |
| non-recoverable failure | tested restore path | release gate report with MTTR |
Map this to NIST AI RMF governance language and OWASP LLM technical risks to keep both security and engineering aligned. S15 S16 S3 S4
Cyber Pulse framing helps in enterprise conversations because it forces teams to assess more than prompt injection. The model spans identity and authentication, access management, data security, agent security posture, and threat detection/response. If one dimension is missing, risk treatment is incomplete. S4
6.1 Governance cadence that actually works
The cadence that works best in practice is two-lane:
- Weekly engineering risk review: incidents, near misses, budget anomalies.
- Monthly governance review: policy exceptions, tool inventory changes, audit trail quality.
Without cadence, governance drifts quietly.
6.2 Threat modeling prompts I use in review meetings
I ask these explicitly and require written answers:
- Which tools can trigger irreversible side effects?
- What is the blast radius if approval logic fails open?
- Can retrieved context indirectly manipulate tool behavior?
- What is the containment plan for compromised MCP endpoints?
- Can we reconstruct decision lineage from logs in under 15 minutes?
7. Observability Model: Beyond “we have logs”
The difference between good and bad agent operations is not telemetry volume. It is incident answerability.
Minimum schema for each run
run_idworkflow_iduser_request_idtool_nametool_risk_classapproval_requiredapproval_decisioncheckpoint_idcost_estimatelatency_ms
For practical interoperability, add a stable schema prefix for GenAI events and keep attribute naming consistent across services. OTel semantic convention work for generative AI is still evolving, so treat your telemetry schema as versioned contract and review it quarterly. S17 S20
SLO model to start with
| Domain | Metric | Trigger |
|---|---|---|
| Reliability | workflow success rate | below 98% in rolling 24h |
| Latency | p95 run latency | above SLA for two windows |
| Safety | approval reject-rate shift | abrupt baseline deviation |
| Quality | human rework rate | sustained increase |
| Economics | cost per successful run | +20% week-over-week |
| Recovery | restore MTTR | exceeds target threshold |
Use OTel semantic conventions so metrics and traces remain comparable across services over time. S6 S17
Operational note from Microsoft observability guidance: avoid enabling sensitive telemetry in production by default unless you have explicit governance controls, because prompts and tool arguments can contain regulated data. Also validate identity credential behavior in production environments; defaults that are convenient in development are often unsafe for production assumptions. S6
8. War Stories: What Breaks First in Real Programs
Story 1: The Budgetless Pilot
Everything looked great until traffic doubled. Then one prompt variant triggered longer reasoning loops and cost tripled in three days.
Fix: hard budgets enforced in middleware plus alerts on budget violations.
Story 2: Approvals on the Wrong Tools
Team approval-gated read-only tools but left write tools ungated due to implementation convenience.
Fix: classify by blast radius, not by ease of implementation.
Story 3: Traces Without Causality
They had traces, but no stable correlation between agent step and external side effect.
Fix: propagate run_id across every tool adapter and outbound integration.
Story 4: “Checkpoint Enabled” but Restore Untested
The feature existed in code. Restore path failed in production because state-shape assumptions changed.
Fix: restore drill becomes mandatory release gate.
Story 5: MCP Side Door
A new MCP server introduced data egress path outside normal governance reviews.
Fix: MCP integration uses same vendor/security review workflow as any external integration.
Story 6: Memory Poisoning Through Trusted-Looking Content
The system passed standard prompt injection tests and still drifted because long-lived memory accepted manipulated content from a trusted-looking source.
Fix: treat memory writes as privileged operations, add source trust scoring, and require periodic memory hygiene jobs with anomaly detection.
9. 90-Day Enterprise Rollout Plan
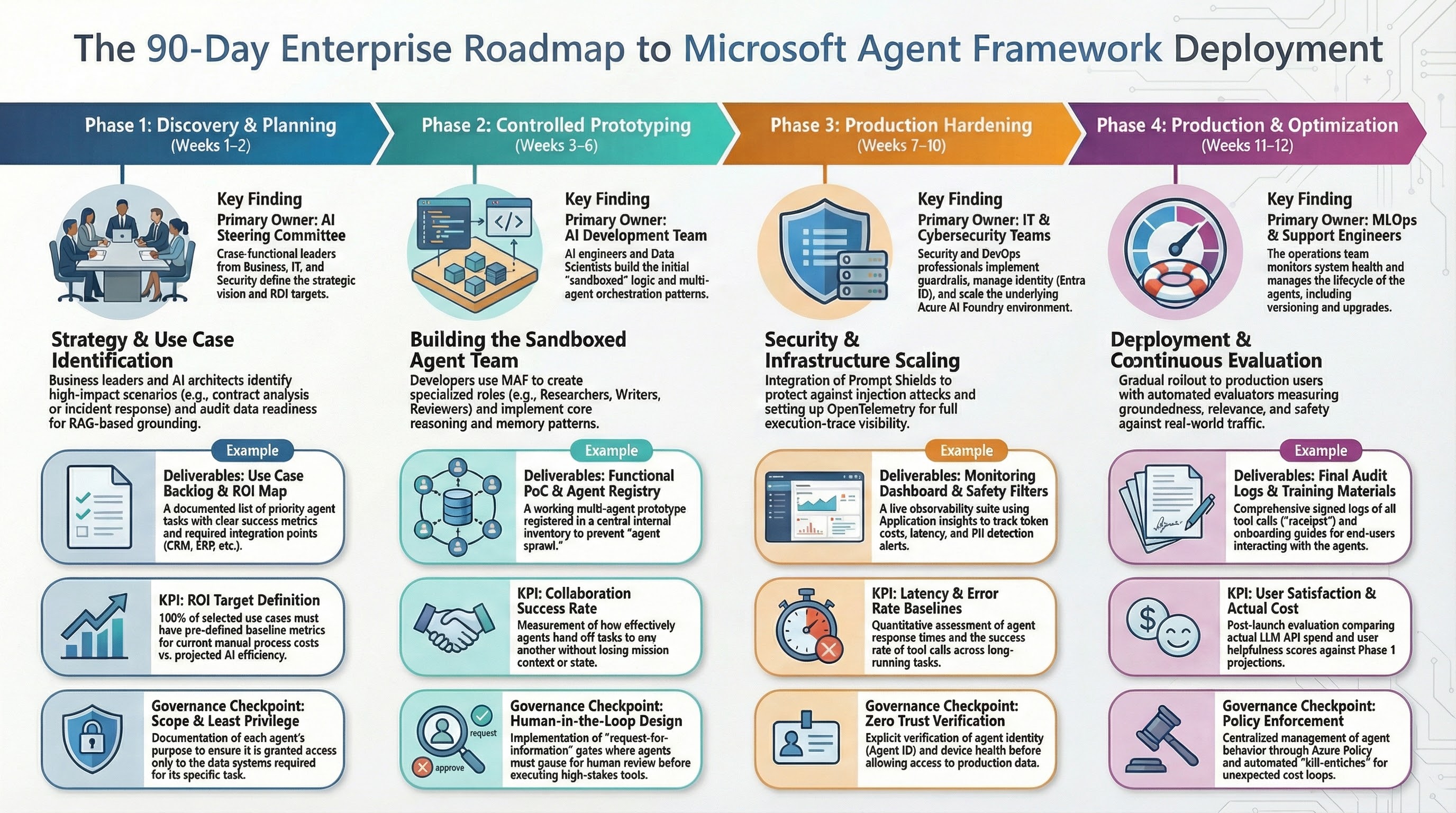
| Phase | Timeline | Deliverables | Exit Criteria |
|---|---|---|---|
| Foundation | Days 1-20 | architecture baseline, identity model, telemetry baseline, first pilot | trace/log/metric completeness proven |
| Controlled pilot | Days 21-45 | one workflow with approval gates and rollback path | no uncontrolled side effects |
| Hardening | Days 46-70 | checkpoint drills, policy tests, load tests, runbooks | reliability and policy gates pass |
| Rollout | Days 71-90 | progressive production rollout with SLO/cost alerts | SLOs met for two release cycles |
gantt
title 90-Day Microsoft Agent Framework Rollout
dateFormat YYYY-MM-DD
axisFormat %d %b
section Foundation
Architecture, identity, telemetry :done, phase1, 2026-02-23, 20d
section Controlled Pilot
HITL approvals and rollback path :active, phase2, after phase1, 25d
section Hardening
Checkpoints, runbooks, load tests :phase3, after phase2, 25d
section Rollout
Progressive production and SLO controls :phase4, after phase3, 20d9.1 What to measure each phase
- Foundation: telemetry completeness and contract stability.
- Controlled pilot: side-effect safety and reviewer throughput.
- Hardening: checkpoint restore success and MTTR.
- Rollout: SLO compliance and cost discipline.
10. Production-Readiness Checklist (Go/No-Go)
- Sensitive tool classes are approval-gated or explicitly exempted with owner sign-off.
- Authorization controls are enforced in middleware, not prompt text.
- Run budgets are hard limits, not recommendations.
- Restore drills pass on the current release candidate build.
- On-call runbook includes manual override and rollback decisions.
- Trace/event model supports incident reconstruction in under 15 minutes.
- Cost per successful run is visible to engineering and product stakeholders.
- MCP integrations are inventory-reviewed and network-constrained.
If any item is not true, delay autonomy expansion.
Closing Perspective
The teams that win with agent systems in 2026 are not the teams with the flashiest demos.
They are the teams that build boring reliability under stress:
- clear ownership,
- hard policy boundaries,
- tested recovery,
- actionable observability,
- and governance that does not depend on tribal memory.
When a run fails at 3 AM, the quality bar is simple: can your team explain what happened, why it happened, and resume safely without chaos?
If yes, you are on the right path.
Source Mapping
- S1: Microsoft Agent Framework Reaches Release Candidate
- S2: Microsoft Agent Framework Overview
- S3: A new era of agents, a new era of posture (Microsoft Security)
- S4: Cyber Pulse: An AI Security Report
- S5: Agent Middleware
- S6: Observability
- S7: Human-in-the-Loop Workflows
- S8: Workflows - Checkpoints
- S9: AI Agent Orchestration Patterns (Azure Architecture Center)
- S10: Microsoft Agent Framework Workflows Overview
- S11: Running Agents
- S12: Using function tools with human in the loop approvals
- S13: Workflows Orchestrations - Sequential
- S14: Using MCP Tools with Agents
- S15: NIST AI RMF Playbook
- S16: OWASP Top 10 for LLM Applications v1.1
- S17: OpenTelemetry Semantic Conventions
- S18: Model Context Protocol (Anthropic)
- S19: Model Context Protocol Security Best Practices
- S20: OpenTelemetry GenAI Semantic Conventions