So, What is This Presidio Thing?
Alright, let’s get technical. Presidio is an open-source library from Microsoft for finding and anonymizing PII. Think of it like a two-part system:
- The Analyzer Engine: This is the detective. It scans your text and looks for anything that looks like PII—names, phone numbers, credit cards, you name it. It’s not just one big regex; it’s a whole team of “recognizers” that use a mix of NLP (like spaCy), regular expressions, and even checksums to be extra sure.
- The Anonymizer Engine: This is the guy with the big black marker. Once the Analyzer finds the PII, the Anonymizer scrubs it out. But it’s smarter than just deleting things. You can tell it how to anonymize. You can redact, mask, replace with fake data, or even encrypt it if you need to get the original data back later.
The best part? It’s all pluggable. You don’t like the default NLP model? Swap it out. Need to find a super-specific, internal-only customer ID format? You can write your own recognizer for it. This is good, because it means you’re not stuck with whatever Microsoft decided was a good idea in 2018.
Why Should I Care?
Look, nobody gets excited about PII detection. You do it because you have to. Your boss comes to you talking about GDPR or HIPAA, and you just need to make the problem go away. This is where Presidio is useful.
- Healthcare: They use it to scrub patient data from clinical notes for research, so they don’t violate HIPAA. One cancer center in Australia used it to process over 50,000 documents, getting F1-scores around 0.84 to 0.90. Not bad for a free tool.
- Finance: Banks and fintech use it to clean up customer support tickets and transaction data before their data science teams get their hands on it. This means fewer chances for an intern to accidentally see a million credit card numbers.
- AI/LLMs: This is the big one now. Everyone is building their own GPT, and you really don’t want to train your shiny new AI on your customer list or internal passwords. Presidio is perfect for cleaning your training data or for building a “privacy layer” that sanitizes user prompts before they hit an external API like OpenAI.
Performance is actually decent, too. We’re talking under 100ms for a typical paragraph, which is fast enough for most real-time work.
Show Me the Code, Stop Talking
Okay, okay. Here is the “get it done” version.
First, install the thing. You need the analyzer, the anonymizer, and an NLP model from spaCy.
# Install the magic
pip install presidio_analyzer presidio_anonymizer
# Download the brain (the spaCy model)
python -m spacy download en_core_web_lg
Now, let’s use it. It’s pretty simple.
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
# 1. Create the detective
analyzer = AnalyzerEngine()
# 2. Create the guy with the marker
anonymizer = AnonymizerEngine()
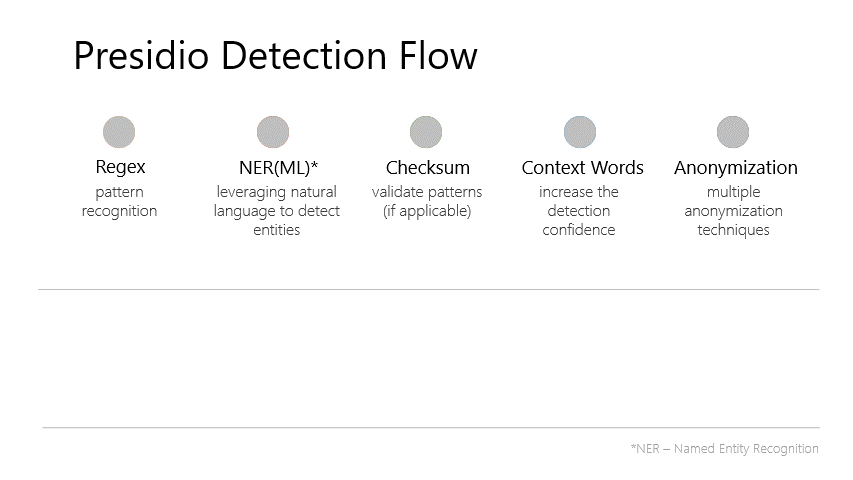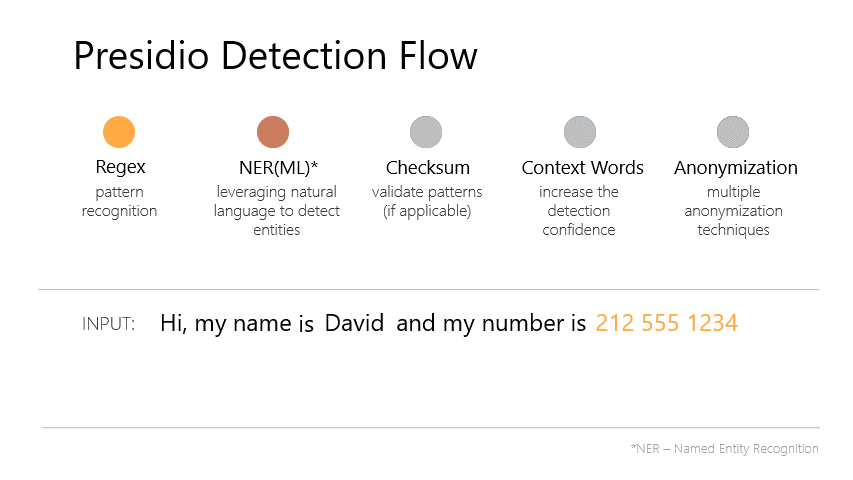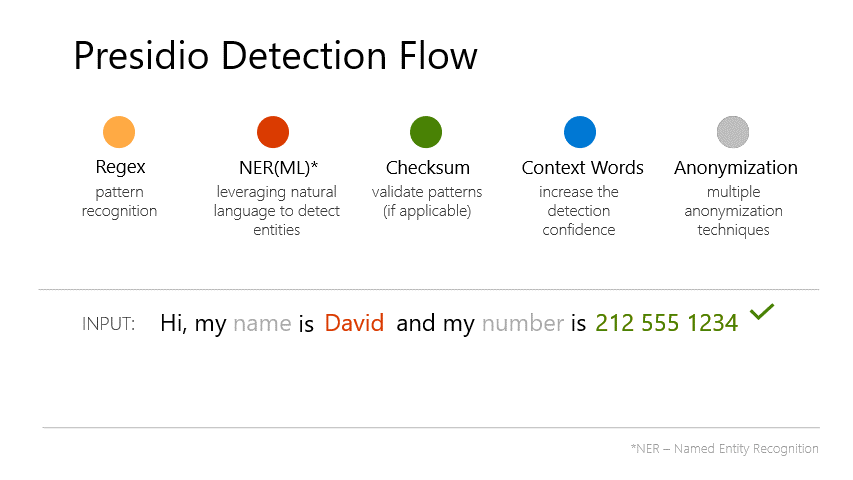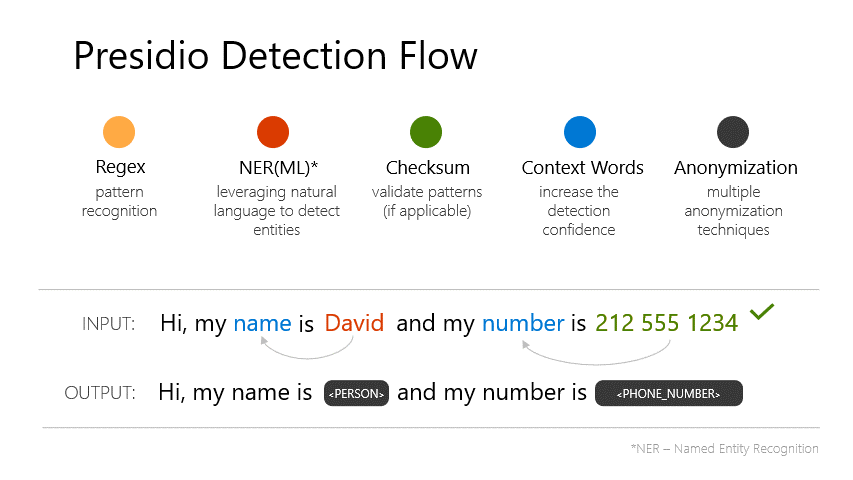
my_text = "My name is Ivan Petrov and you can call me at 555-123-4567. My lawyer is John Smith."
# 3. Find the bad stuff
analyzer_results = analyzer.analyze(text=my_text, language='en')
# analyzer_results is just a list of things it found
print(f"Found PII: {analyzer_results}")
# 4. Make it disappear
anonymized_output = anonymizer.anonymize(
text=my_text,
analyzer_results=analyzer_results
)
# By default, it just replaces with the entity type. Boring.
print(f"Anonymized Text: {anonymized_output.text}")
# >> Anonymized Text: My name is <PERSON> and you can call me at <PHONE_NUMBER>. My lawyer is <PERSON>.
But the default anonymizer is… let’s call it “uninspired”. We can do better. Let’s mask the phone number and just replace names with a generic placeholder.
from presidio_anonymizer.entities import OperatorConfig
anonymized_output = anonymizer.anonymize(
text=my_text,
analyzer_results=analyzer_results,
operators={
"PERSON": OperatorConfig("replace", {"new_value": "[REDACTED]"}),
"PHONE_NUMBER": OperatorConfig(
"mask", {"type": "mask", "masking_char": "*", "chars_to_mask": 12}
)
}
)
print(f"Better Anonymized Text: {anonymized_output.text}")
# >> Better Anonymized Text: My name is [REDACTED] and you can call me at ************. My lawyer is [REDACTED].
And what about that custom ID I mentioned? Of course your company has one. Here is how you teach Presidio to find “EMP-123456”.
from presidio_analyzer import Pattern, PatternRecognizer
# Define the regex. Yes, I know I said no regex. I lied. But it's small.
employee_id_pattern = Pattern(name="employee_id", regex=r"EMP-\d{6}", score=0.8)
# Create a recognizer for it
employee_recognizer = PatternRecognizer(
supported_entity="EMPLOYEE_ID",
patterns=[employee_id_pattern]
)
# Add it to the detective's brain
analyzer.registry.add_recognizer(employee_recognizer)
# Now it works on new text
text_with_id = "Employee EMP-867530 needs a password reset."
results = analyzer.analyze(text=text_with_id, language='en')
print(results)
# >> [type: EMPLOYEE_ID, start: 9, end: 19, score: 0.8]
See? Not so bad. You can get pretty far with just this.
The “Okay, Now We’re a Serious Enterprise” Architecture
So you built a nice little prototype. It works. You showed your manager. Big mistake. Now they want to use it everywhere. In production. Scaled across 20 services. Welcome to enterprise development. Fun times.
If you really have to do this properly, you can’t just run a Python script. You need the whole circus: CI/CD, Kubernetes, policy enforcement, autoscaling… the works. Here is the lazy genius’s checklist for not getting fired.
- Containerize Everything: Put the analyzer and anonymizer in their own Docker containers. Microsoft even provides official ones. Don’t reinvent the wheel.
- Deploy on Kubernetes: Of course. Because “enterprise”. Use a Helm chart to manage the deployment. This makes it easy to configure and update.
- CI/CD Pipeline is Not Optional:
- Test your custom recognizers. You don’t want to push a bad regex that brings down the whole system.
- Use the
presidio-evaluatortool to automatically check your accuracy. If your changes make PII detection worse, fail the build. - Scan your container images for vulnerabilities. Sign them with something like Cosign. Your security team will thank you (by leaving you alone).
- Autoscaling is Your Friend:
- Use a Horizontal Pod Autoscaler (HPA) in Kubernetes. Set it to scale based on CPU usage. When a thousand requests hit at once, it will just spin up more pods. Problem solved (mostly).
- If you’re really fancy, you can use KEDA to scale based on queue length or HTTP traffic.
- Policy and Secrets Management:
- Use something like OPA Gatekeeper or Kyverno to enforce rules on your Kubernetes cluster (e.g., “no containers running as root”).
- Don’t hardcode encryption keys in your code. Please. Use a real secrets manager like Azure Key Vault or HashiCorp Vault, and inject them into your pods.
This sounds like a lot of work (and it is), but it’s less work than explaining to your CISO why you leaked the entire customer database.
Final Thoughts: Is It Worth It?
So, is Presidio the magic bullet that solves all data privacy problems? No. Of course not. Nothing is. You still have to think. You have to test it on your own data, because your data is always weirder than you think.
But is it a damn good framework that saves you from building a PII scanner from scratch? Yes. It’s flexible, it’s free, and it’s backed by a big company, which means it probably won’t disappear next year.
It hits that sweet spot for the lazy genius: powerful enough to solve a serious problem, but simple enough that you can get a proof-of-concept running in an afternoon. And that means more time for… well, whatever it is you do when you’re not writing code.
P.S. - Yes, I know you could use Google DLP or AWS Macie. They are great if you love vendor lock-in and unpredictable monthly bills. Presidio you can run anywhere, even on a server under your desk. Just saying.