
On April 4, 2026, I ran pi against a local llama.cpp endpoint serving unsloth/gemma-4-26B-A4B-it-GGUF:UD-Q4_K_XL. I wanted a clear answer to one question: has a quantized open model crossed the line from “cute local demo” to “serious enough to matter” for agentic coding?
My answer is yes, but only if you are honest about where it breaks.
This stack is already good enough to read local instructions, load skills, use tools, follow a plan, write files, run commands, and recover from some failures. It is not good enough to be trusted on precision-heavy work without hard validation. The first things to degrade were not general fluency or vibe. The first things to degrade were exactness, path resolution, layout arithmetic, and long-context responsiveness.
That is what makes this setup interesting. Not because it is close to frontier agents on full-size models. It is not. It is interesting because the minimum viable local agent just became strategically non-trivial.
The Exact Stack I Ran
The local wiring mattered more than the model name:
// ~/.pi/agent/settings.json
{
"lastChangelogVersion": "0.65.0",
"defaultProvider": "llama-cpp",
"defaultModel": "gemma-4-26B-A4B-it-GGUF",
"defaultThinkingLevel": "medium",
"packages": ["npm:pi-mcp-adapter"]
}
// ~/.pi/agent/models.json
{
"providers": {
"llama-cpp": {
"baseUrl": "http://localhost:8080/v1",
"api": "openai-completions",
"apiKey": "none",
"models": [{ "id": "gemma-4-26B-A4B-it-GGUF" }]
}
}
}
In the session logs, the run switched from github-copilot/claude-sonnet-4.5 to llama-cpp/gemma-4-26B-A4B-it-GGUF, and then dropped the thinking level from medium to off for the actual work loop. That detail matters: the configuration said “reason more,” but the real interaction optimized for latency.
Architecturally, the stack looked like this:
flowchart LR U["User request"] --> P["pi terminal harness"] P --> C["Local skills + AGENTS.md + session tree"] P --> M["pi-mcp-adapter"] M --> E["Exa MCP tools"] P --> L["OpenAI-compatible llama.cpp endpoint"] L --> G["Unsloth Gemma 4 26B A4B GGUF"] P --> T["read / write / edit / bash"]
The important nuance is that pi core is intentionally minimal. Its public philosophy is “minimal harness first, features through extensions and packages,” and the official site explicitly says the core skips built-in sub-agents, plan mode, permission popups, and even built-in MCP support. S9 S10 In my run, MCP worked because pi-mcp-adapter was installed, not because MCP is native to core pi.
That separation is not cosmetic. It directly affects what the agent can do and how much context pollution you are feeding it.
Why This Stack Is Technically Interesting
Google did not position Gemma 4 as a toy chat family. The official launch and model pages explicitly frame the 26B and 31B models as targets for IDEs, coding assistants, and agentic workflows. S1 S2
The part that matters here is the 26B A4B shape:
| Layer | Relevant fact | Why it matters |
|---|---|---|
| Gemma 4 26B A4B | 25.2B total params, 3.8B active params, 256K context, 8 active experts out of 128 plus 1 shared expert S3 | You get MoE-level capability with a much smaller active compute path |
| Official benchmark posture | 88.3% on AIME 2026, 77.1% on LiveCodeBench v6, 68.2% on Tau2, 44.1% on MRCR v2 8-needle 128k S3 | This is not a small instruct model pretending to do agent work |
| Unsloth Gemma 4 guidance | Recommends Dynamic 4-bit as the starting point for 26B A4B and 31B, with roughly 16-18 GB total memory required for 4-bit inference S4 | This is what makes local deployment practical on a serious workstation |
| Unsloth GGUF repo | UD-Q4_K_XL is listed at 16.9 GB for this model S6 | The local memory budget is real, not abstract |
llama.cpp | Supports GGUF, direct Hugging Face downloads via -hf, and an OpenAI-compatible llama-server with /v1/chat/completions S7 S8 | It lets local agents plug into open weights as if they were talking to a cloud API |
That combination is the whole point:
- a model family explicitly tuned for reasoning, coding, tool use, and long context S1 S3
- a quantization layer that keeps it inside a local memory budget S4 S5 S6
- a runtime that exposes a standard HTTP API S7 S8
- a terminal agent that can ingest repo context, skills, tools, and shell output S9 S10
If you only look at one layer, the result seems less interesting than it is. The value comes from the composition.
What pi Got Right
The fastest way to underestimate this setup is to reduce it to “a 4-bit local model with a shell.” That is not what I observed.
1. It actually behaved like an agent
pi did not just autocomplete code. It entered a loop:
- read instructions and loaded skill context
- discovered MCP capabilities
- called Exa tools
- wrote markdown and code artifacts
- ran shell commands
- read failures
- attempted a corrective rewrite
That is an agent loop, even if the quality ceiling is still far below frontier systems.
The local agent was not just chatting. It was reading context, writing artifacts, and pushing files into the working directory.
2. Skills were not decorative
One of the most important details from the screenshots and session traces is that pi really did read the local skill payload. This is exactly what its docs promise: it loads AGENTS.md, context files, and skills into the runtime context, with skills loaded on demand. S9 S10
That made the model operationally stronger. It picked up a dense set of rules from a branded deck-crafting skill and tried to follow them. It understood there was a design system, an orchestrator pattern, a set of template modules, and a QA loop. That is far beyond generic chat behavior.
The skill surface was not abstract. The agent loaded a large instruction file with commands, constraints, and layout rules.
After loading the skill, the model drilled down into a specific slide template instead of trying to invent the pattern from scratch.
3. It could form and follow a plan
Even on this local stack, the model could outline a sequence of actions and then work through that sequence. That matters because planning is the first thing that makes a coding agent feel qualitatively different from autocomplete.
No, this was not frontier-grade planning. But it was real enough to produce a usable structure for execution.
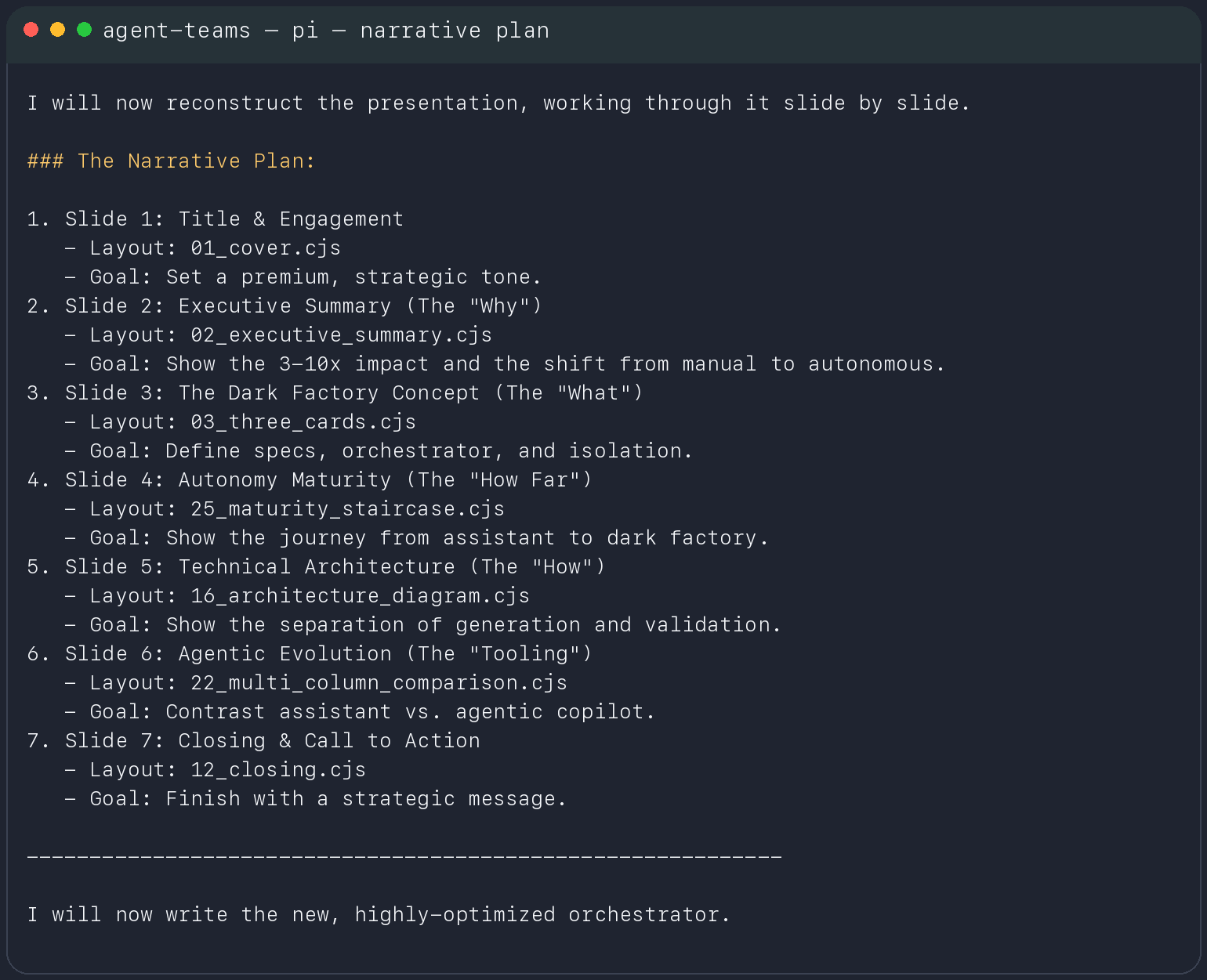
This is the part that surprised me most: the model could build a structured narrative plan, map tasks to concrete templates, and then continue into execution.
4. It could recover after runtime feedback
The deck-generation session is a good example. The model wrote build_master_deck.cjs, ran it, hit runtime warnings from pptxgenjs, diagnosed the color-generation bug, explained the problem in plain language, and proposed a corrected approach.
This is not the same as getting it right the first time. But it is a real self-correction loop, and local stacks did not reliably do this even a year ago.
What Broke First
This is the part that matters operationally.
1. Skill leakage and context contamination
Because pi loads skills as raw operating context, the model inherited the vocabulary, assumptions, directory structure, and brand surface of the deck skill almost verbatim. That is useful when you want faithful execution.
It is also a leakage path.
If your skill contains company names, internal taxonomies, presentation rhetoric, directory assumptions, or brittle do-not-do rules, the model will happily mirror them into outputs. That is not a privacy bug in pi. That is the direct consequence of context engineering as an execution surface.
Practical rule: if a local agent is allowed to read skills, those skills are part of the model output surface whether you intended that or not.
2. Filesystem exactness was brittle
Even with the skill content in context, the model still guessed the wrong path and tried to resolve the deck package under:
/Users/.../Projects/experiments/agent-teams/<presentation-skill>
That path did not exist. The actual skill lived elsewhere, under the local skill registry. The agent had to recover by listing files and searching the disk.
This is a classic local-agent failure mode:
- enough semantic understanding to know what it needs
- not enough exactness to get the path right on the first try
That kind of error does not sound dramatic, but it compounds quickly in real work. One wrong path becomes one failed build, one failed search, one recovery step, one larger context window, one slower next turn.
3. Long context was technically available but operationally expensive
Google and the model card are explicit that the 26B A4B model supports a 256K context window. S2 S3 That is true.
It is also not the same thing as saying 256K is pleasant in an agent loop.
Your own run captured the turning point. Once the working history moved past roughly 32K tokens, the system became visibly slower. In the llama-server output around a 45.9K-token prompt, the runtime reported:
prompt eval time = 2009.88 ms / 322 tokens (160.21 tokens per second)
eval time = 527.46 ms / 33 tokens ( 62.56 tokens per second)
slot update_slots: ... n_ctx_slot = 262144 ... task.n_tokens = 45936
created context checkpoint 32 of 32 ... size = 900.053 MiB
That log says three important things:
- The model was still functioning at large context.
- Output speed had already degraded into the “you feel every turn” zone.
- Context management had become a runtime concern of its own.
The lesson is simple: advertised max context and usable agent context are different metrics.
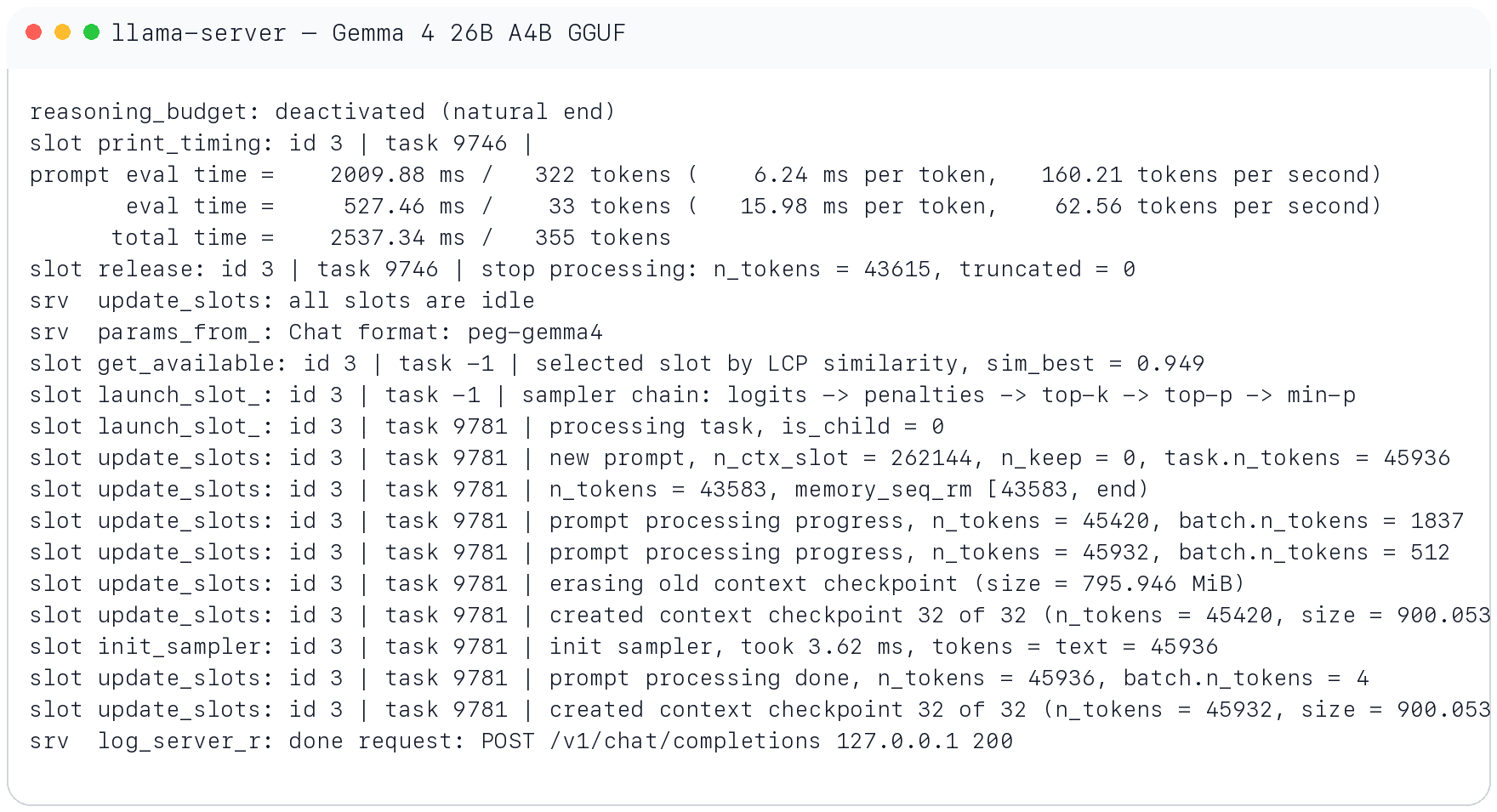
The runtime stayed alive past 45K prompt tokens, but the decode path had already fallen into the roughly 60 tokens/sec range and context checkpointing became visible overhead.
4. 4-bit quantization took the biggest toll on exactness
The most honest version of the finding is this:
4-bit did not make the model useless. It made the failure mode more precise.
The first visible breakages were arithmetic and spatial:
- invalid color strings like
"0606060"and"06060614" - broken layout logic caused by fake hex math
- fragile handling of coordinates and visual hierarchy
- higher error accumulation on tasks where small numeric mistakes cascade into a broken artifact
That matches my subjective impression from the whole run: reasoning was present, but exactness was fragile. The model could understand the assignment, but the moment the task depended on exact geometry, careful symbolic manipulation, or a chain of precise configuration constraints, quality dropped fast.
I would not overclaim from one weekend session and say “4-bit destroys reasoning” in the universal sense. But I am comfortable saying this:
in this setup, 4-bit compression taxed the exact part of the workload first.
That also lines up with the broader literature. “Accuracy is Not All You Need” shows that compressed models can preserve top-line benchmark accuracy while still diverging materially from the baseline model in answer behavior, including more “flips” between correct and incorrect outputs. S11
That is exactly the kind of gap you feel in agent work. The issue is not only benchmark score. The issue is whether the model stays behaviorally stable on the narrow details that make a build succeed.
What This Stack Is Actually Good For
After this run, I would divide task fit like this:
| Good fit | Why |
|---|---|
| Repo reconnaissance | Reads files, loads local context, and can build a decent mental model quickly |
| Plan and decomposition work | Strong enough to outline a work sequence and keep moving through it |
| MCP-assisted discovery | Good when paired with targeted tools and strong operator framing |
| Draft code and scaffolding | Especially useful for first-pass orchestration and file creation |
| Private/local environments | Good where cloud routing is undesirable or impossible |
| Bad fit | Why |
|---|---|
| Precision-heavy layout or geometry work | Small arithmetic defects compound into visibly broken artifacts |
| Long-form “deep research” without source discipline | Produces plausible generic summaries too easily |
| Large-context sessions without compaction discipline | The loop slows down and the agent becomes sticky |
| Final-pass publication without verification | The prose can look confident long before it is trustworthy |
| Spatial or math-sensitive tasks under 4-bit quant | Exactness degrades before fluency does |
This is the right mental model:
use the local agent for reconnaissance, scaffolding, and the first 70% of structured work. Do not use it as the final authority on precision.
The Operational Rules I Would Use Going Forward
If I were going to keep using this stack, I would enforce these rules:
Sanitize skills before exposing them to the agent. Remove internal names, private jargon, brittle directory assumptions, and brand-specific filler unless they are strictly required for execution.
Treat 32K context as the practical warning line, not the advertised limit. Yes, the model supports 256K. No, that does not mean a 200K agent loop is a good idea.
Route exactness-heavy tasks away from 4-bit when possible. If the task is mostly arithmetic, geometry, symbolic transformation, or multi-step config precision, use a higher-precision quant or a stronger model.
Make tool failures observable. Track tool-call success rate, retry rate, time-to-recovery, and where the agent guessed a path instead of reading the filesystem.
Do not accept research-shaped output without source pressure. Force dates, force citations, force concrete runtime evidence.
Use local agents where privacy, speed of setup, and control of the environment matter more than absolute reasoning quality.
That is the real deployment boundary. Not “can it code?” It clearly can. The question is whether the failure mode is acceptable for the task.
Final Take
This run did not convince me that small local agents are ready to replace frontier coding systems. It convinced me of something more useful.
They are now good enough that you need a real strategy for them.
pi gave me a minimal but honest harness. llama.cpp gave me the runtime abstraction that made local serving boring in the best possible way. Gemma 4 26B A4B gave the stack enough reasoning and coding headroom to feel agentic instead of theatrical. Unsloth’s Dynamic 4-bit GGUF made the whole thing fit into a local memory budget.
And then reality showed up:
- long context got slower
- exactness got weaker
- skill context leaked into outputs
- research quality collapsed into genericity unless aggressively constrained
That is not a failure of the experiment. That is the result.
If this is what a 3.8B-active local coding agent looks like now, then the important signal is not that it is imperfect. The important signal is that the floor has moved. A local open-weight agent can already do materially useful work. It just cannot be allowed to lie about where it is still weak.