
Most agent-memory systems still do the lazy thing: store raw interaction history, retrieve a few chunks, and hope the base model compresses the mess at inference time. PlugMem starts from a much stronger assumption. The useful part of experience is sparse, structured, and should be compiled before retrieval.
That is why this paper matters. PlugMem was submitted to arXiv on February 6, 2026, published on the Microsoft Research site on March 6, 2026, and the PDF metadata marks it as an ICML 2026 proceedings paper. As of April 5, 2026, the code and benchmark artifacts are public. The claim is ambitious but concrete: a single task-agnostic memory module, attached unchanged to very different agents, can beat both raw-memory baselines and several task-specific memory systems while using much less agent-side context. S1 S2 S3 S4
The real contribution is not “graph memory.” It is a different unit of memory. PlugMem does not treat raw trajectories, entities, or text chunks as the thing to retrieve. It treats knowledge as the thing to retrieve: semantic facts, procedural know-how, and episodic evidence. That makes it much closer to a memory compiler than to a vector database for chat history. S2 S3
Reality Check: What PlugMem Is, and What It Is Not
PlugMem is a plugin memory module for LLM agents. The paper positions it as task-agnostic because the same architecture is evaluated unchanged on:
- LongMemEval for long-horizon conversational memory,
- HotpotQA for multi-hop knowledge retrieval,
- WebArena for browser-agent behavior and transfer. S2 S3
That framing is fair at the memory abstraction layer. The paper really is asking whether one memory design can survive across heterogeneous tasks.
But it is not fair to read “task-agnostic” as “everything-agnostic.”
The public repo is still tightly coupled to a specific research stack: Qwen served through vLLM, NV-Embed-v2 for embeddings, OpenAI or Azure paths for some calls, and a disk-backed file layout for persisted nodes. The README even presents the system as “plug-and-play” with six lines of code, which is true at the call site but hides real runtime assumptions underneath. S4 S10
That distinction matters because the paper is strong. The artifact is useful. But the repo is a research implementation, not a hardened memory platform.
Why Raw Memory Retrieval Breaks Down
The paper starts from a problem most agent builders have already felt in practice: raw memory retrieval is bad at two things at the same time.
First, it is too verbose. Raw trajectories drag irrelevant observations, UI noise, and low-signal actions back into context. Second, it is too weakly aligned to decisions. Even if a past trajectory contains the right answer, the useful part may be an abstract rule, a preference, or a short procedure rather than the literal text span that happened to appear before. S2 S3
PlugMem’s answer is to move compression earlier in the pipeline.
Instead of asking the base model to perform abstraction every time a decision is needed, PlugMem performs abstraction during memory construction and stores the result in a knowledge-centric graph. The paper explicitly contrasts this with GraphRAG-like approaches by saying that knowledge, not entities or chunks, becomes the unit of organization and access. S2
That is the right design bet. Most agent failures around memory are not caused by a shortage of history. They are caused by retrieving the wrong level of abstraction.
Failure mode: If you store every trace and postpone abstraction until inference, the agent spends context on noise and still misses reusable policy.
Mitigation: Compile memories into reusable semantic and procedural units before retrieval, while keeping episodic links as provenance rather than as the primary retrieval payload.
How PlugMem Actually Works
The paper formalizes each interaction step as:
e_t = (o_t, s_t, a_t, r_t, g_t)
M_epi = [e_t]_(t=1..T)
where observation, state, action, reward, and subgoal are standardized into a unified episodic representation. That standardized episode is then transformed into three linked memory types:
- semantic memory for propositional knowledge;
- procedural memory for prescriptive how-to knowledge;
- episodic memory for source evidence and traceability. S3
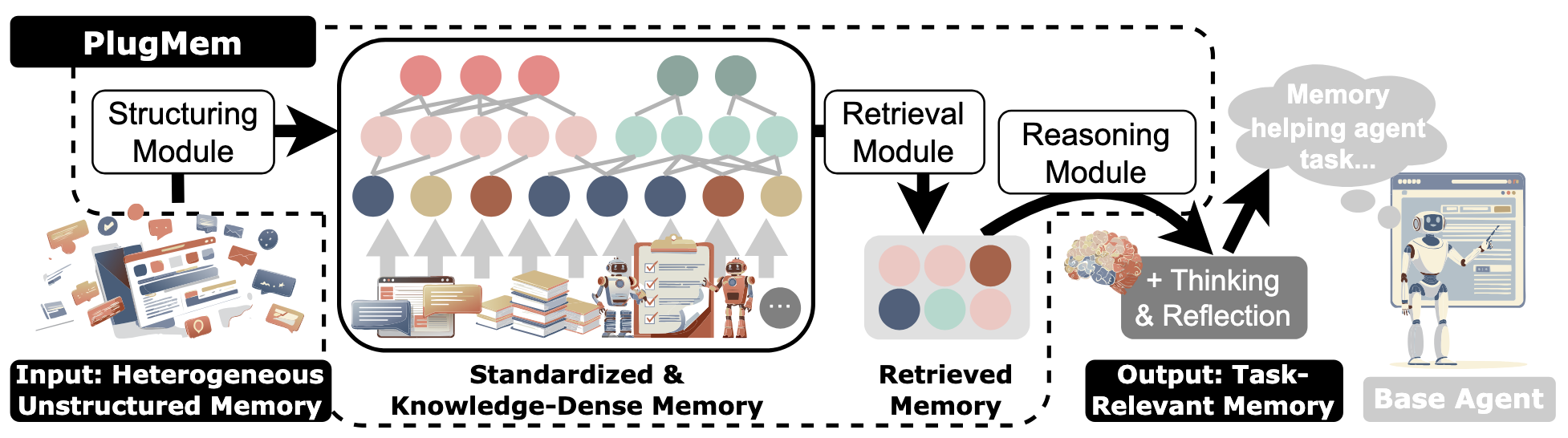
Public PlugMem pipeline figure from the authors’ repo. It matches the paper’s three-stage decomposition: structuring, retrieval, and reasoning. S4
1. Structuring is a write-time LLM pipeline, not a logging step
This is the first place where the public code is useful because it shows what “memory structuring” actually means operationally.
Memory.append() does not simply append an event. It calls LLM-based routines to infer a subgoal, a reward, and an updated state for every step. It also checks the similarity between consecutive subgoals and splits the trajectory into a new episodic segment when the similarity falls below 0.75. In other words, the graph is built through interpretation, not through raw transcription. S5
Then Memory.close() walks those episodic segments and extracts:
- semantic memories per step via
get_semantic(...); - one procedural memory per segmented trajectory via
get_procedural(...). S5
That implementation detail matters because it makes the tradeoff explicit: PlugMem buys retrieval quality by paying more at write time.
2. The graph stores knowledge at multiple levels, with provenance
At insert time, MemoryGraph.insert(...) persists episodic nodes, creates semantic nodes and tag nodes, creates or updates subgoal nodes, and attaches procedural memories to those subgoals. The result is a graph where procedural knowledge is anchored to abstract subgoals, semantic knowledge is reachable through tags and similarity, and episodic traces remain available as supporting evidence. S6
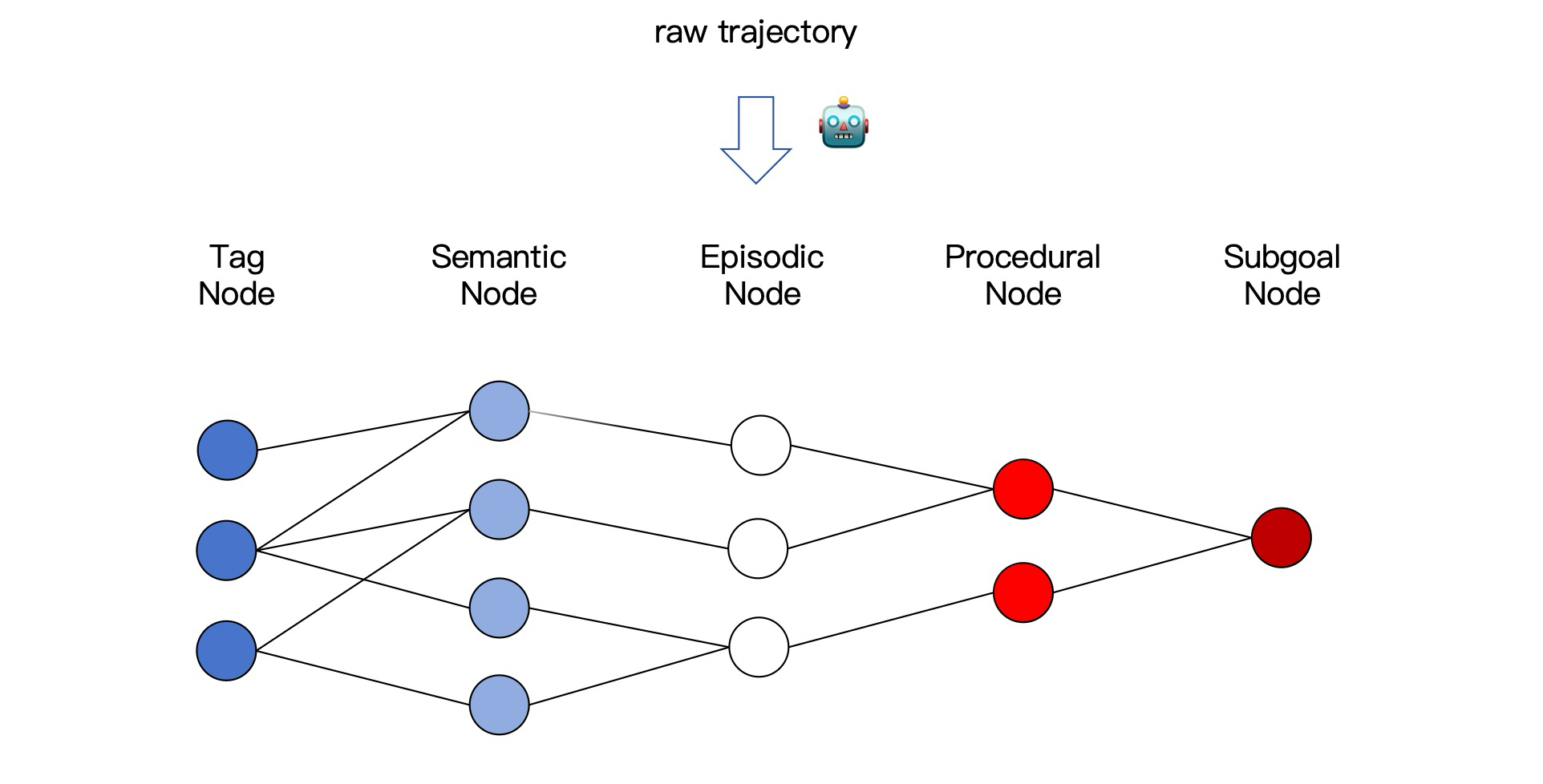
Public memory-graph figure from the authors’ repo. The important move is not just “graph structure” but the separation of semantic, procedural, and episodic memory with explicit links between them. S4
This is where PlugMem departs from most memory add-ons. The graph is not merely an indexing trick. It is an attempt to preserve three different kinds of reusable signal:
- what is true;
- what tends to work;
- where that knowledge came from.
3. Retrieval is abstraction-aware before it becomes generative
The retrieval path is also cleaner than most agent-memory papers.
retrieve_memory(...) first asks the retrieval planner for next_subgoal and query_tags, then selects a memory mode: semantic, procedural, or episodic. Semantic retrieval mixes two channels:
- direct similarity between the current observation and semantic-memory embeddings;
- a tag-voting path that promotes semantic nodes connected to relevant tags. S6
Procedural retrieval is routed through subgoals. Episodic retrieval is only used when the system believes raw experience is actually needed. Finally, retrieve_and_reason(...) simply calls retrieve_memory(...) and then hands the assembled prompt to an LLM reasoning step. S6
That last part is important. The reasoning module is not the memory system. It is a compression layer over retrieved knowledge.
The paper’s ablations make this unusually clear:
- remove retrieval and performance collapses;
- remove structuring and retrieval gets much worse;
- remove reasoning and quality drops only moderately, but the token budget explodes. S3
On LongMemEval, for example, PlugMem reaches 75.1 accuracy with 362.58 average memory tokens, while No Reasoning still gets 72.4 accuracy but needs 9478.59 tokens. On HotpotQA, PlugMem gets 61.4 EM / 74.1 F1 at 81.6 tokens, while No Reasoning gets 59.3 / 71.8 at 635.1 tokens. That is a very strong signal that reasoning is primarily controlling how efficiently retrieved knowledge is consumed, not replacing retrieval quality. S3
What the Benchmarks Actually Prove
One of the best parts of the paper is that it does not stop at task scores. It also defines a utility-per-cost view of memory:
PMI(a* ; m | s) = log2(P_mem(a* | s, m) / P_base(a* | s))
rho(a*, m) = PMI(a* ; m | s) / |m|
The point is simple: a memory system should be judged not only by whether it helps, but by how much decision-relevant utility it adds per injected token. S3
That framing is much better than the usual “my agent got a better score with more retrieved context” benchmark theater.
LongMemEval: better accuracy with an order-of-magnitude smaller memory payload
On LongMemEval, PlugMem reports 75.1 accuracy with 362.58 average memory tokens and 1.6e-2 information density.
That beats:
- Vanilla Retrieval at 63.6 accuracy and 3742.52 tokens,
- A-Mem at 61.0 and 4225.85 tokens,
- Zep at 71.2,
- LiCoMemory at 73.0 with 5914.85 tokens. S3
The key point is not just that PlugMem is better. It is that it is better while shipping far less text back into the base model.
HotpotQA: knowledge abstraction matters even more under tight budgets
On HotpotQA, PlugMem reports 61.4 EM / 74.1 F1 with 81.6 average memory tokens and 1.4e-1 information density.
That beats strong graph-oriented or knowledge-oriented baselines such as:
- RAPTOR at 56.7 / 69.7 with 806.3 tokens,
- PropRAG at 57.8 / 72.1 with 626.1 tokens,
- HippoRAG2 at 60.0 / 73.3 with 595.1 tokens. S3
This is exactly the sort of benchmark where knowledge-centric retrieval should win. The answer is not a long trace. It is a small number of linked facts surfaced at the right abstraction level.
WebArena: the strongest systems signal in the paper
WebArena is where the paper becomes much more interesting than a classical RAG result because it tests transfer and reuse rather than just static retrieval.
PlugMem reports:
- Shopping:
52.6 / 58.4online/offline success, - GitLab:
51.4 / 55.2, - Multi-site:
20.0 / 21.6, - with 301 average memory tokens and 1.4e-3 information density. S3
Two things matter here.
First, the offline protocol is not trivial replay. The paper explicitly uses an online/offline split so a later agent can inherit a pre-built memory graph, approximating cold-start transfer. Second, Multi-site is still hard. PlugMem improves it, but does not magically solve compositional browser-agent difficulty. S3
That is exactly the kind of result I trust. Strong gains, but still bounded by the task.

PlugMem’s benchmark story is best read as “more decision-relevant utility per token,” not as “graph memory wins by default.”
The Most Important Ablation Result
The ablations answer the only systems question that really matters: which component is doing real work?
- Retrieval is the bottleneck.
No Retrievalcollapses hardest across all three tasks. On HotpotQA it falls to 20.0 EM / 24.3 F1 and even produces negative information density. S3 - Structuring changes what can be retrieved.
No Structuringhurts every benchmark because the retriever is then operating over weaker memory units. S3 - Reasoning is a compression/control layer.
No Reasoningoften preserves a decent amount of task quality but becomes dramatically less efficient in token cost. S3
This is the correct mental model for PlugMem:
- structuring decides the memory substrate;
- retrieval decides whether useful memory is reachable;
- reasoning decides whether retrieved memory is turned into compact, actionable guidance.
That decomposition is one of the strongest things in the paper because it tells you exactly where to instrument and exactly where to expect failures.
What the Public Repo Reveals That the Paper Does Not
The paper is the architecture. The repo is the reality check.
1. Task-agnostic is not backend-agnostic
The public code path is opinionated. utils.py defaults to qwen-2.5-32b-instruct, expects a Qwen-compatible vLLM endpoint, relies on NV-Embed-v2 for embeddings, and supports OpenAI, Azure, and OpenRouter branches through environment variables. The README setup instructions mirror those same assumptions. S4 S10
That does not invalidate the task-agnostic claim. It just means the public artifact is task-agnostic at the memory design level, not at the deployment-stack level.
2. The public scorer is less expressive than the paper’s scoring story
The paper presents a richer decision model involving relevance, utility, and efficiency. The repo exposes a general ValueBase interface with components for importance, relevance, recency, return, and credibility.
But the current implementation is materially narrower than that interface suggests:
ValueBase.evaluate(...)computes a credibility term and then does not include it in the final returned sum;- the LongMemEval value functions set almost every component except relevance to zero. S7 S8
In other words, the public retriever is currently much closer to a relevance-dominant system with extension points than to a fully realized multi-factor value model.
That gap is worth stating plainly because it is the difference between “promising memory framework” and “drop-in general memory runtime.”
3. Memory evolution exists, but it is still heuristic-heavy
The paper describes standard graph operations, including update and delete, and the appendix discusses semantic-graph updating. The code path update_semantic_subgraph(...) shows what that means in practice:
- collect merge candidates through shared tags,
- cap candidate counts to avoid blow-up,
- score pairs by similarity,
- merge via an LLM call,
- soft-deactivate low-credibility nodes instead of physically deleting them. S3 S6
That is a reasonable research design. It is not yet a mature knowledge-maintenance subsystem.
4. There are small but telling signs of research-grade roughness
The repo has a few signals that are normal in research code but would be uncomfortable in production:
EpisdoicNodeis misspelled in the public node class;SubgoalNode.embeddingreferences_cache_embeddinginstead of_cache_embedding_gate, which looks like a real bug;- several node types lazy-load embeddings from disk, which is practical for experiments but can become an operational bottleneck. S9
That is not a criticism of the paper. It is simply the maturity curve. The idea is ahead of the implementation.
Three Implementation Patterns Worth Stealing
You do not need to adopt the entire repo to learn something useful from PlugMem.
1. Post-episode knowledge compilation for persistent assistants
If you are building a support agent, executive assistant, or long-lived internal copilot, PlugMem’s strongest reusable pattern is this:
- keep raw interaction traces as ephemeral logs;
- after the session, compile them into semantic facts and procedural routines;
- keep episodic links only for provenance and dispute resolution.
That avoids the classic failure mode where every future turn drags half the old conversation back into context.
A minimal integration shape looks like this:
mg = MemoryGraph()
mem = Memory(goal=goal, observation=observation_t0)
for action_t0, observation_t1 in trajectory:
mem.append(action_t0, observation_t1)
mem.close()
mg.insert(mem)
guidance = mg.retrieve_and_reason(
goal=goal,
subgoal=subgoal,
state=state,
observation=current_observation,
)
That flow is essentially what the README advertises, but the operational lesson is that the compile step should happen after the interaction, not inline on every user-facing token path. S4 S5 S6
Tradeoff: You pay extra write-time LLM and embedding cost in exchange for cheaper, cleaner retrieval later.
Failure mode: Low-signal sessions create bad semantic memories that persist too long.
Mitigation: Gate inserts by session length, confidence, or explicit success criteria before promoting knowledge into the persistent graph.
2. Semantic-first multi-hop memory for research and QA agents
HotpotQA is a good proxy for research assistants because it forces the system to compose distant facts rather than recover one lucky chunk.
The useful pattern is:
- use semantic nodes as the primary retrieval surface;
- use tags as a second retrieval channel, not as the only index;
- keep episodic evidence attached so the final answer can still be grounded. S3 S6
That is stronger than flat vector retrieval because it separates:
- the thing you want to reason over;
- the evidence that justifies it.
Tradeoff: You introduce another abstraction layer that can merge too aggressively or hide contradictory evidence.
Failure mode: Two superficially similar facts collapse into one semantic node and destroy the distinction the task actually needs.
Mitigation: Retain provenance edges, prefer soft deactivation over destructive overwrite, and require evidence review for contradictory merges.
3. Cold-start transfer for browser or workflow agents
WebArena is not just a benchmark result. It shows a practical rollout pattern: let an agent learn online, optionally seed it with high-quality human demonstrations, then hand the resulting memory graph to later agents operating in related tasks. S3 S4
That is a much better way to think about agent memory in workflow systems than “save the transcript forever.”
The principle is:
- store reusable strategy at the procedural layer;
- store factual environment knowledge at the semantic layer;
- do not hardwire fragile low-level execution details unless they are truly stable.
Tradeoff: You get stronger transfer, but only if the stored procedures are abstract enough to survive task variation.
Failure mode: The memory graph turns into a warehouse of brittle UI-specific scripts.
Mitigation: Promote subgoal-level procedures such as “search by product ID before browsing categories,” not DOM-specific click sequences.
Operational Risks and Mitigations
If you are tempted to productionize this architecture, these are the real traps.
| Risk | Why It Happens | Mitigation |
|---|---|---|
| Extraction hallucinations become durable memory | Structuring is LLM-mediated, so wrong abstractions can be persisted | Store provenance, add confidence or reviewer gates, and allow soft deactivation |
| Merge logic destroys distinctions | Semantic evolution is similarity- and tag-driven, not truth-grounded | Separate contradictory facts, keep sibling links, and never merge without evidence retention |
| Write-time cost erases the runtime win | append() and close() perform multiple LLM and embedding calls | Batch compaction offline or on idle paths instead of synchronous request paths |
| Task-agnostic abstraction misses domain constraints | A generic memory schema cannot encode every workflow nuance | Layer domain policies on top of PlugMem instead of forcing them into the memory substrate |
| The repo looks simpler than the deployment reality | Public code hides model-serving, embedding, and disk-layout assumptions | Treat the repo as a reference implementation and build your own runtime contracts explicitly |
The biggest strategic mistake would be to read this work as “general memory is solved.” It is not. What PlugMem solves better than most prior work is the representation and retrieval problem.
Observability and SLO Model
If you cannot measure whether the memory graph is helping, you do not have a memory system. You have a narrative.
The minimum telemetry contract I would require looks like this:
memory_compile_tokens_per_episodememory_compile_latency_mssemantic_nodes_created_per_episodeprocedural_nodes_created_per_episoderetrieved_memory_tokenssemantic_hit_rateprocedural_hit_rateevidence_backed_answer_ratedelta_success_rate_vs_no_memorysoft_deactivation_ratemerge_accept_rate
The most important production metric is not graph size. It is decision uplift per retrieved token, which is the operational cousin of the paper’s information-density metric. S3
I would use release gates like these:
| Dimension | Release Gate |
|---|---|
| Retrieval efficiency | Median retrieved-memory payload stays below 512 tokens on the target workflow |
| Decision quality | Memory-enabled success or answer quality improves by at least 5% over the no-memory control |
| Latency | p95 retrieve-plus-reason latency stays within the route budget |
| Integrity | Fewer than 1% of audited decisions rely on stale or contradictory promoted memories |
| Stability | Merge or deactivation jobs complete without corrupting the retrievable index |
Failure mode: Teams measure only task score and node counts.
Mitigation: Track the relationship between retrieved token budget, decision uplift, and provenance quality.
A Rollout Plan That Actually Makes Sense
The clean rollout is not “turn on autonomous memory everywhere.”
Phase 1: Instrument and shadow
- keep your current agent behavior unchanged;
- log candidate trajectories and decisions;
- run PlugMem structuring offline;
- inspect the semantic and procedural nodes it would have created.
Checkpoint: If the extracted memories are noisy, redundant, or obviously over-abstracted, do not move to online retrieval yet.
Phase 2: Insert-only mode
- persist episodic, semantic, and procedural memory;
- disable retrieval in the user-facing path;
- measure compile cost, graph growth, and merge quality.
Checkpoint: If graph growth is linear noise and not compressive knowledge, your structuring prompts or filters are wrong.
Phase 3: Semantic and procedural canary
- enable retrieval for one workflow slice;
- compare against a no-memory control;
- keep episodic retrieval narrow and evidence-focused.
Checkpoint: If answer quality improves but token cost explodes, the retriever is fine and the reasoning compressor is weak.
Phase 4: Transfer and evolution
- test new agents or cold-start tasks against a pre-built memory graph;
- add update and merge jobs carefully;
- keep rollback cheap by versioning the graph.
Checkpoint: If transfer works only when the task is nearly identical, your procedural memories are too literal.
That last step is where PlugMem becomes strategically interesting. The moment one agent can hand off compact, reusable knowledge to another, memory stops being just a convenience feature and starts becoming infrastructure.
Bottom Line
PlugMem is one of the better agent-memory papers I have read in a while because it focuses on the right failure mode.
The central idea is not bigger context and not smarter chunk retrieval. It is that agent memory should be organized around reusable knowledge rather than raw traces.
The paper backs that up with three strong points:
- a clean decomposition into structuring, retrieval, and reasoning; S3
- benchmark wins that are meaningful because they are tied to token-efficient memory use, not just end scores; S3
- a public implementation that is concrete enough to audit, even if it is still clearly research-grade. S4 S5 S6
My read is straightforward.
PlugMem is not a finished memory platform. The repo is too opinionated, too heuristic-heavy, and a little too rough around the edges for that. But the abstraction is right. Retrieval over compact semantic and procedural knowledge, with episodic provenance kept in reserve, is a much stronger design than stuffing old trajectories back into the prompt and calling it memory.
That is why I think this work matters. It is not claiming that agents remember better because they stored more. It is claiming they remember better because they stored the right thing.