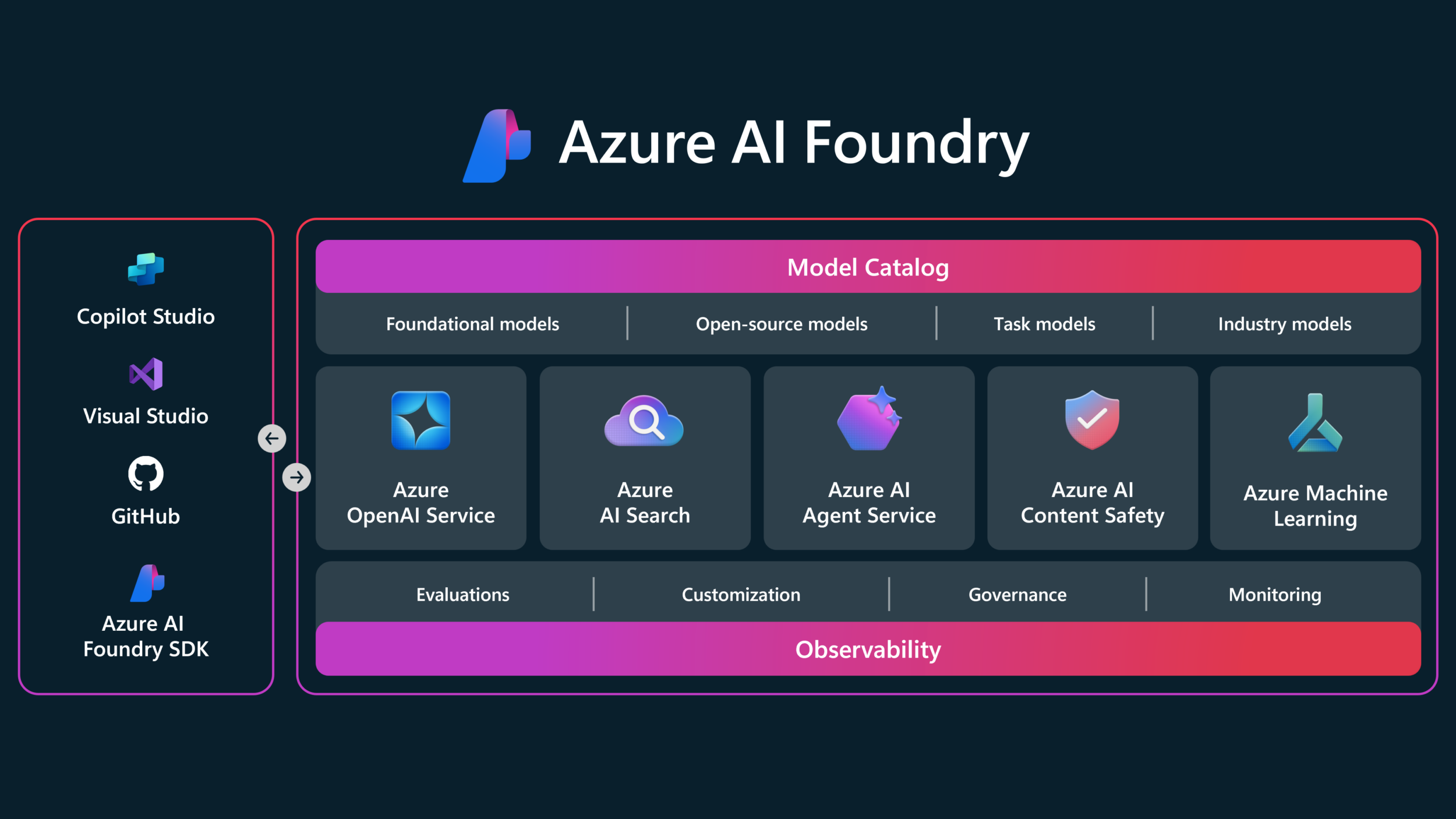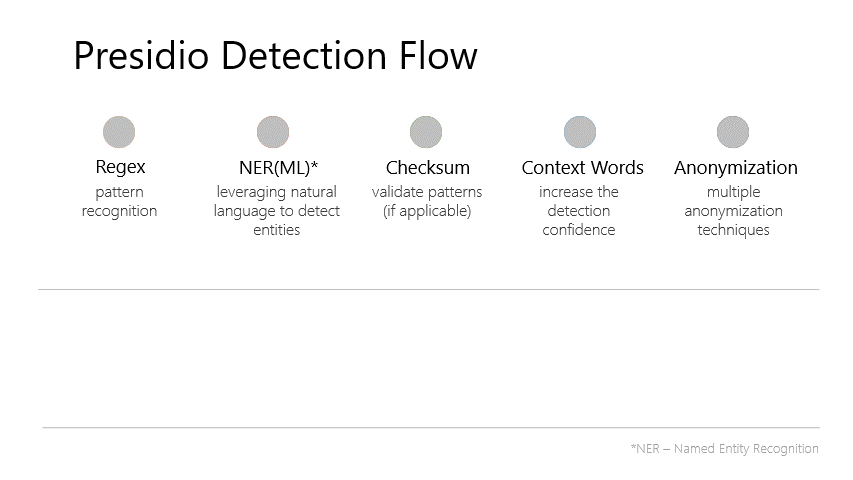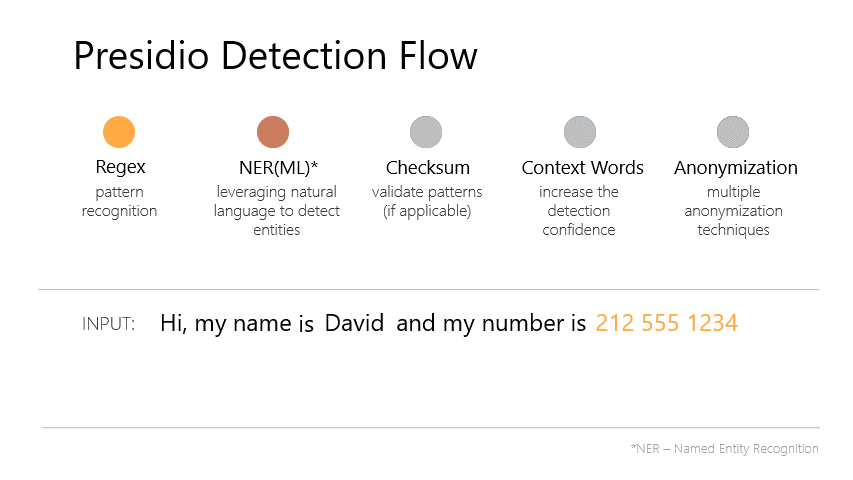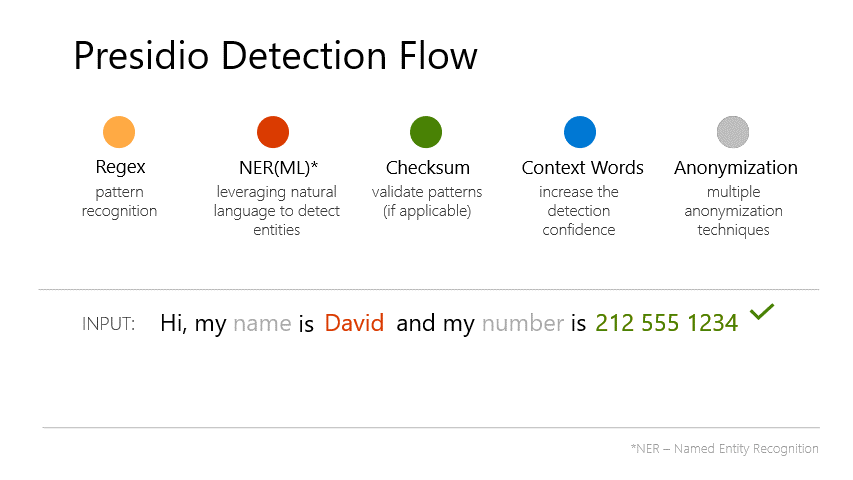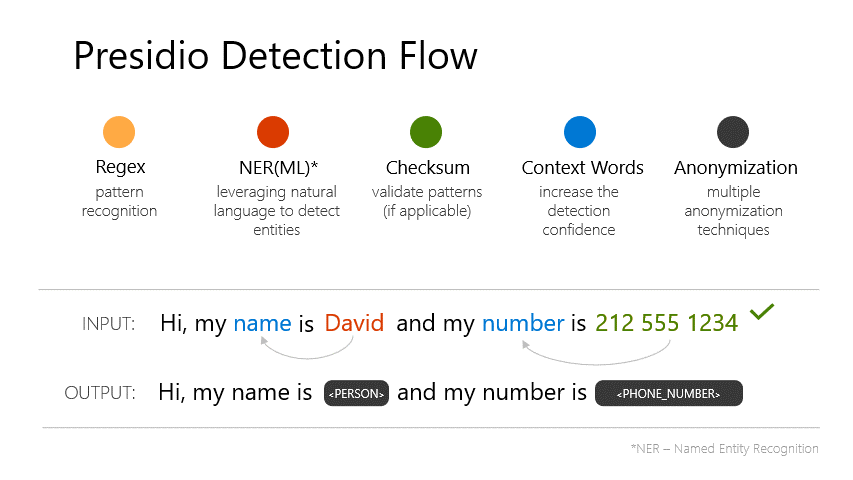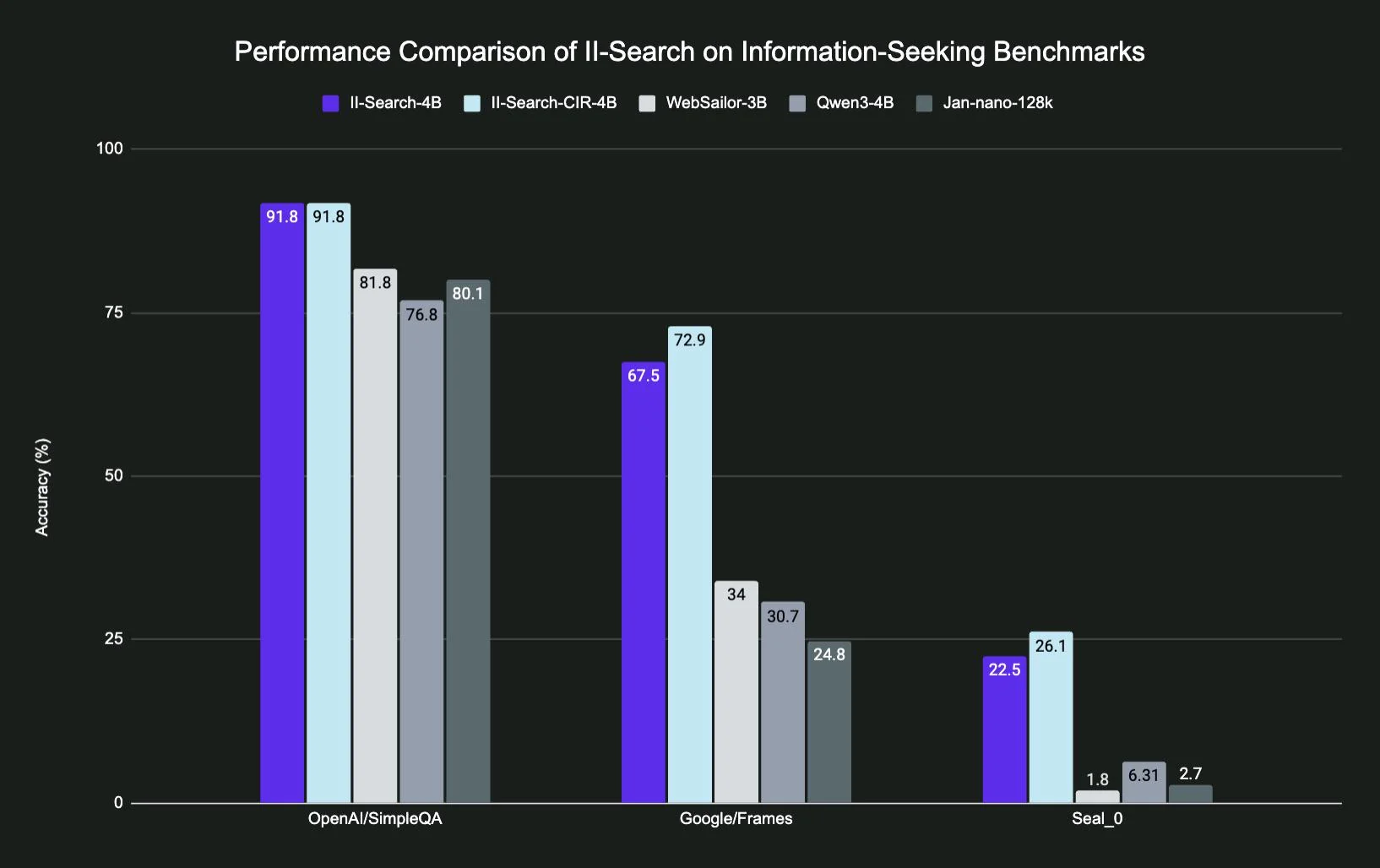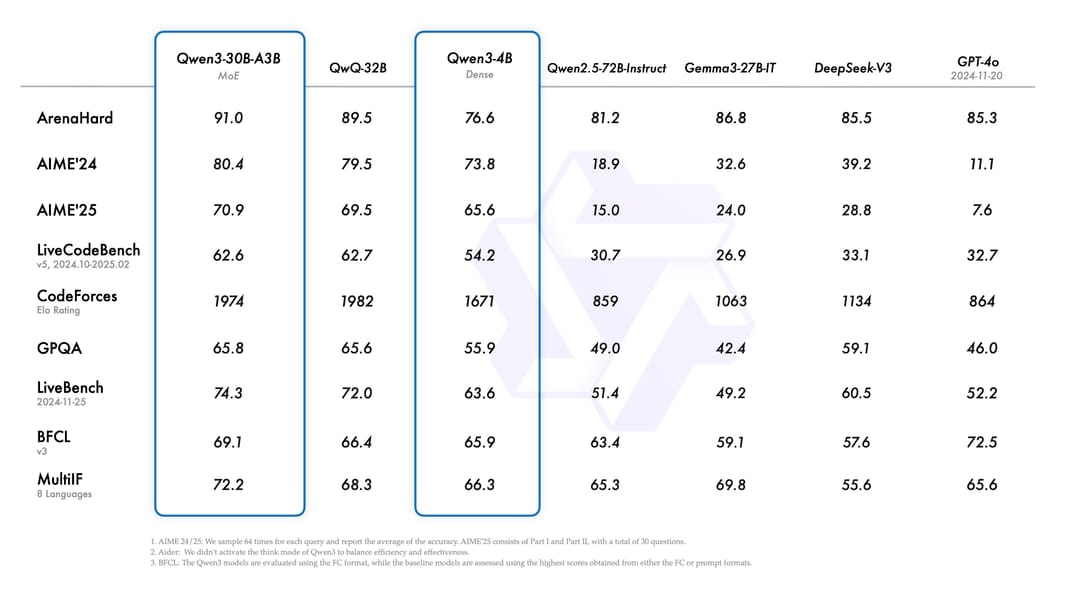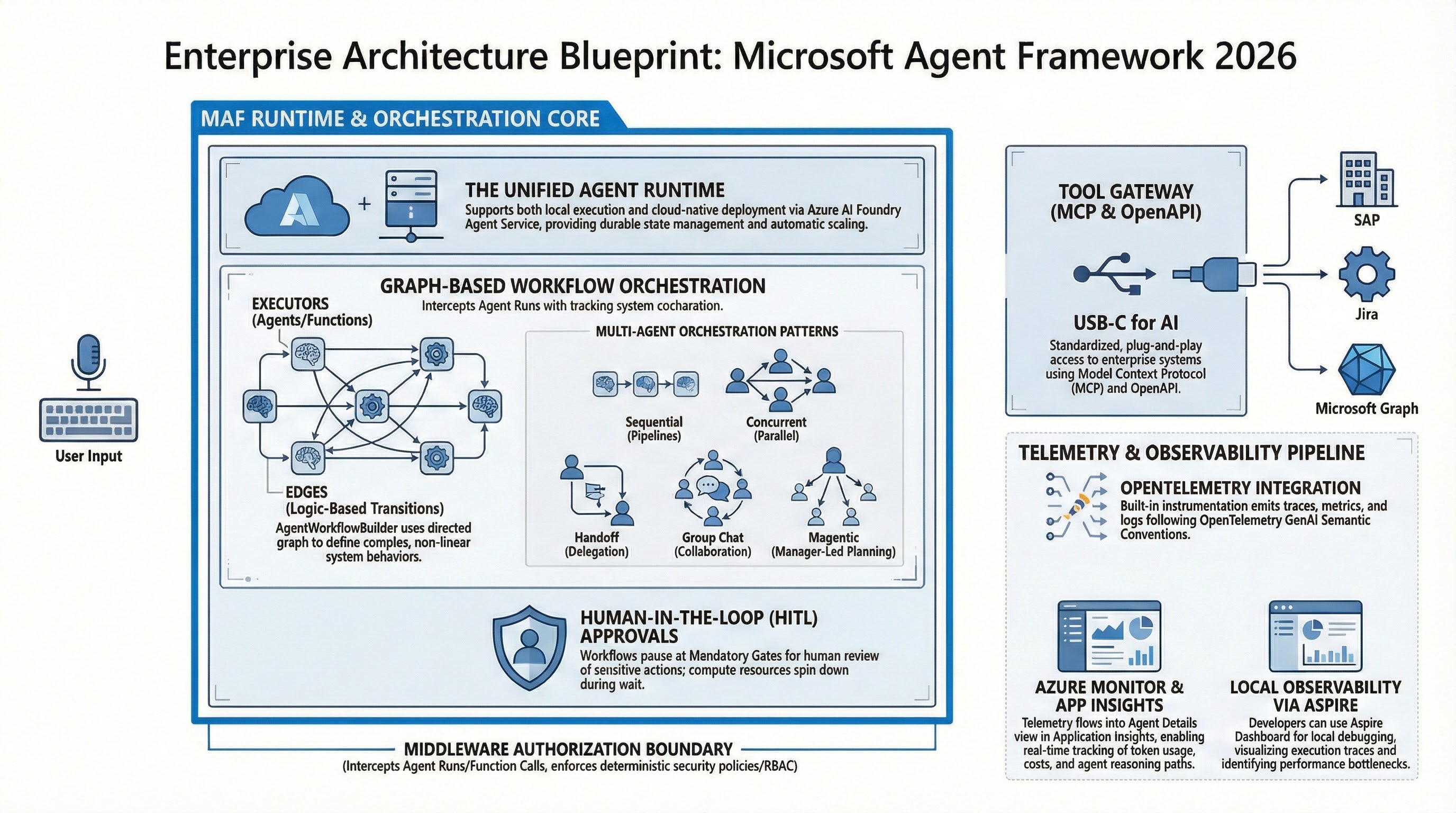
Microsoft Agent Framework in 2026: Enterprise Architecture Playbook
Reading time: ~45 min | Audience: platform leads, principal engineers, AI architects, security teams | Primary goal: build agent systems that stay stable under real enterprise pressure Preface: Why I Wrote This Version Quick context on why this exists. I have read too many agent posts that sound convincing and then collapse in real enterprise environments. Usually they miss one of three things: They stop at demos. They show code without operations. They draw architecture without incident behavior. This version is for teams that already shipped something and now need clear answers in design review, security review, and on-call: ...