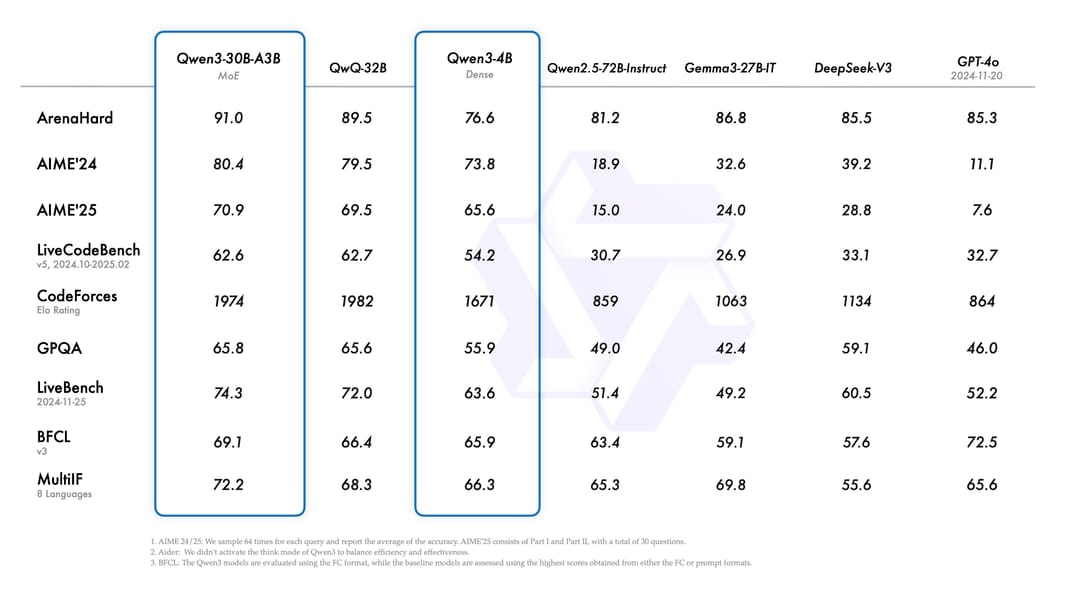
Qwen3-30B-A3B represents a paradigm shift in large language model efficiency, achieving flagship-level performance with only 3.3 billion active parameters from a 30.5 billion total parameter pool. This Mixture-of-Experts (MoE) model, released by Alibaba’s Qwen team, demonstrates that intelligent parameter activation can outperform brute-force scaling, scoring 91.0 on ArenaHard while using 10x fewer active parameters than comparable dense models. The model’s hybrid thinking architecture enables controllable reasoning depth, supporting both rapid responses and deep analytical tasks through dynamic computational allocation.
Complete architectural specifications reveal sophisticated MoE design
The Qwen3-30B-A3B employs a 128-expert architecture with 8 experts activated per token, achieving an optimal balance between specialization and efficiency. The model comprises 48 transformer layers with Grouped Query Attention (GQA), featuring 32 query heads mapped to 4 key/value heads for an 8:1 compression ratio. This attention mechanism significantly reduces memory requirements while maintaining performance. The architecture uses RMSNorm with pre-normalization and implements QK-layernorm across all layers for enhanced stability during training and inference.
The positional encoding leverages Rotary Position Embeddings (RoPE) with ABF enhancement, enabling native context lengths of 32,768 tokens. Through YaRN (Yet another RoPE N) scaling with a factor of 4.0, the model extends its context window to 131,072 tokens, with the latest variants supporting up to 262,144 tokens. The tokenizer employs byte-level BPE with a vocabulary of 151,669 tokens, supporting 119 languages and dialects - a significant expansion from the 29 languages in Qwen2.5.
The MoE routing mechanism implements token-choice routing without shared experts, using global-batch load balancing to prevent expert collapse. Each forward pass activates only 3.3 billion parameters, approximately 11% of the total, while maintaining access to the full capacity for specialized knowledge. The activation function uses SwiGLU (Swish-Gated Linear Units), providing smooth gradients and improved training dynamics compared to traditional ReLU variants.
Technical innovations center on hybrid reasoning architecture
The model’s most distinctive innovation is its hybrid thinking framework, seamlessly integrating two operational modes within a single model. In thinking mode, the model generates step-by-step reasoning chains enclosed in special <think> tokens, allowing for complex problem-solving with computational budgets that scale with task difficulty. Non-thinking mode provides rapid, direct responses for simpler queries. Users control mode selection through soft switches (/think and /no_think commands) or by adjusting the thinking budget parameter.
Training methodology represents another significant advancement, utilizing 36 trillion tokens - double the data used for Qwen2.5. The three-stage pretraining pipeline progressively builds capabilities: Stage 1 establishes foundational knowledge with 30+ trillion tokens at 4K context length, Stage 2 intensifies STEM and coding capabilities with 5 trillion specialized tokens, and Stage 3 extends context handling to 32K tokens using high-quality long documents processed through Qwen2.5-VL for text extraction.
The four-stage post-training pipeline demonstrates sophisticated curriculum learning. Stage 1 implements Chain-of-Thought cold start using diverse reasoning datasets. Stage 2 applies reasoning-based reinforcement learning with scaled computational resources and rule-based rewards. Stage 3 fuses thinking and non-thinking capabilities through mixed training, while Stage 4 conducts general reinforcement learning across 20+ tasks for instruction following and safety alignment.
Quantization support showcases remarkable resilience, with GPTQ maintaining less than 1% performance degradation at 4-bit precision on the MMLU benchmark. The model supports AWQ, GGUF, and FP8 formats, with specialized optimization for SGLang and vLLM serving frameworks. The implementation of global load balancing without auxiliary losses prevents quality degradation while ensuring even expert utilization.
Benchmark performance validates architectural efficiency
Performance metrics demonstrate the model’s exceptional efficiency-to-capability ratio. On ArenaHard, Qwen3-30B-A3B achieves 91.0, surpassing QwQ-32B (89.5), DeepSeek-V3 (85.5), and GPT-4o (85.3) despite using dramatically fewer active parameters. Mathematical reasoning shows particular strength with an AIME'24 score of 80.4, increasing to 85.0 in the updated 2507 version. The model achieves a CodeForces Elo rating of 1974, competitive with much larger models.
Inference speed measurements using SGLang reveal impressive throughput scaling. With BF16 precision, the model processes 137 tokens/second for single-token inputs, accelerating to 1,538 tokens/second at 63,488 token batches. FP8 quantization further improves these metrics to 155 and 1,647 tokens/second respectively. Even with aggressive GPTQ-INT4 quantization using the Marlin backend, the model maintains 704 tokens/second at 129K context length.
Memory efficiency analysis shows the model requires 58.5GB VRAM in BF16, reducing to 30.3GB with FP8 and approximately 17.5GB with INT4 quantization. These requirements enable deployment on single high-end consumer GPUs rather than requiring multi-GPU datacenter setups. The MoE architecture enables 100+ tokens/second on Apple M4 Max with quantized versions, demonstrating excellent performance across diverse hardware.
Comparative benchmarks reveal consistent advantages over dense models. The model matches or exceeds Qwen3-32B dense performance while activating only 10% of its parameters. Against other MoE architectures, Qwen3-30B-A3B’s fine-grained 128-expert design provides better specialization than Mixtral’s 8-expert configuration while maintaining lower inference costs than DeepSeek’s 256-expert approach.
Strategic positioning within evolving MoE ecosystem
Within the broader AI landscape, Qwen3-30B-A3B occupies a unique position as the most parameter-efficient model in the 30B class. Compared to DeepSeek-V3’s 671B total/37B active configuration, Qwen3 achieves competitive performance with an order of magnitude fewer parameters. The elimination of shared experts, unlike DeepSeek’s architecture, maximizes routing flexibility while the 128-expert granularity enables more nuanced specialization than Mixtral’s coarser 8-expert design.
The model’s relationship to Chinese AI development reveals sophisticated architectural evolution. Unlike GLM-4.5’s bias-term routing, Qwen3 implements balanced routing without auxiliary losses. Compared to Kimi K2’s emphasis on “lossless long context” with 384 experts, Qwen3 optimizes for reasoning depth with fewer, more capable experts. The thinking budget control mechanism appears unique among current models, providing users unprecedented control over computational resource allocation.
Training data composition shows significant multilingual advancement, supporting 119 languages versus typical Western models’ 8-30 language coverage. The use of synthetic data generated by Qwen2.5-Math and Qwen2.5-Coder for specialized training represents sophisticated self-improvement strategies. The strong-to-weak distillation from larger Qwen3 models (235B-A22B) enables knowledge transfer that maintains competitive performance at dramatically reduced scale.
Architectural borrowing analysis reveals selective adoption of proven techniques. The GQA implementation follows recent Llama developments, while the RoPE with YaRN scaling matches frontier models’ context capabilities. However, the hybrid thinking architecture and dynamic mode switching represent genuine innovations without clear precedent in publicly available models.
Deployment flexibility enables diverse implementation strategies
Production deployment demonstrates remarkable flexibility across hardware configurations. For local deployment, the model runs effectively on RTX 3090 (24GB) with Q4_K_M quantization, achieving reasonable inference speeds. Enterprise deployments benefit from vLLM’s tensor parallelism support, enabling multi-GPU scaling for high-throughput applications. Apple Silicon deployment shows particular promise, with M3/M4 Max systems achieving 100+ tokens/second using unified memory architecture.
Framework support spans the entire deployment ecosystem. Hugging Face Transformers (≥4.51.0) provides standard integration, while SGLang offers 50-100x speed improvements over vanilla Transformers. The vLLM implementation includes specialized --enable-reasoning flags for thinking mode support. Full llama.cpp/GGUF compatibility enables CPU inference on systems with 32GB+ RAM, achieving 20-25 tokens/second on high-speed DDR5.
Quantization strategies reveal careful optimization trade-offs. Q4_K_M GGUF represents the sweet spot at 18.6GB with 2-3% quality loss, while Q8_0 maintains less than 1% degradation at 32GB. AWQ INT4 provides GPU-optimized inference with minimal quality impact. The new Unsloth Dynamic 2.0 quantization promises state-of-the-art compression quality. FP8 block-wise quantization on Ada Lovelace or newer architectures provides 30% size reduction with negligible performance impact.
Cost analysis favors self-hosting for moderate to high usage. At 1 million tokens daily, self-hosting on RTX 3090 costs approximately $150/month versus $450 for API access. Cloud GPU deployment (A100) reaches $2,400/month, making local deployment compelling for sustained usage. The break-even point occurs around 100K tokens/day, below which API access provides better economics.
Fine-tuning capabilities leverage QLoRA through Unsloth, requiring only 17.5GB VRAM for the full 30B model. This enables domain adaptation on consumer hardware, democratizing model customization. Full fine-tuning remains intensive, requiring 120GB+ memory on multi-GPU setups, but the parameter-efficient alternatives provide practical paths for specialization.
Conclusion
Qwen3-30B-A3B exemplifies the next generation of efficient AI architectures, proving that intelligent design trumps raw scale. Its 10:1 total-to-active parameter ratio, combined with sophisticated routing mechanisms and hybrid reasoning modes, delivers frontier model capabilities at dramatically reduced computational costs. The model’s Apache 2.0 licensing, comprehensive framework support, and flexible deployment options position it as a pivotal development in democratizing advanced AI capabilities.
The technical innovations - particularly thinking budget control and seamless mode switching - suggest new directions for controllable AI systems where users actively participate in resource allocation decisions. With deployment feasible on consumer hardware and performance competitive with models requiring datacenter infrastructure, Qwen3-30B-A3B bridges the gap between research ambitions and practical accessibility, establishing new benchmarks for parameter-efficient artificial intelligence.