Qwen3-30B-A3B Deep Dive: How 128 Experts Achieve Frontier Performance at 10% Active Parameters
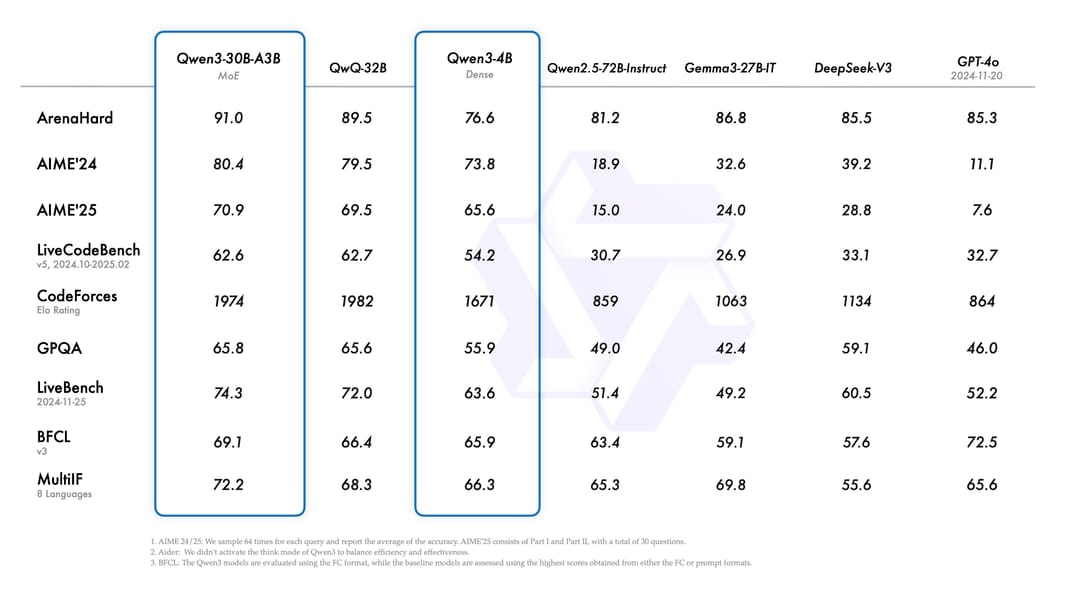
Qwen3-30B-A3B represents a paradigm shift in large language model efficiency, achieving flagship-level performance with only 3.3 billion active parameters from a 30.5 billion total parameter pool. This Mixture-of-Experts (MoE) model, released by Alibaba’s Qwen team, demonstrates that intelligent parameter activation can outperform brute-force scaling, scoring 91.0 on ArenaHard while using 10x fewer active parameters than comparable dense models. The model’s hybrid thinking architecture enables controllable reasoning depth, supporting both rapid responses and deep analytical tasks through dynamic computational allocation. ...