II-Search-4B: A Love Letter to Small Models (Or How I Learned to Stop Worrying and Embrace 4B Parameters)
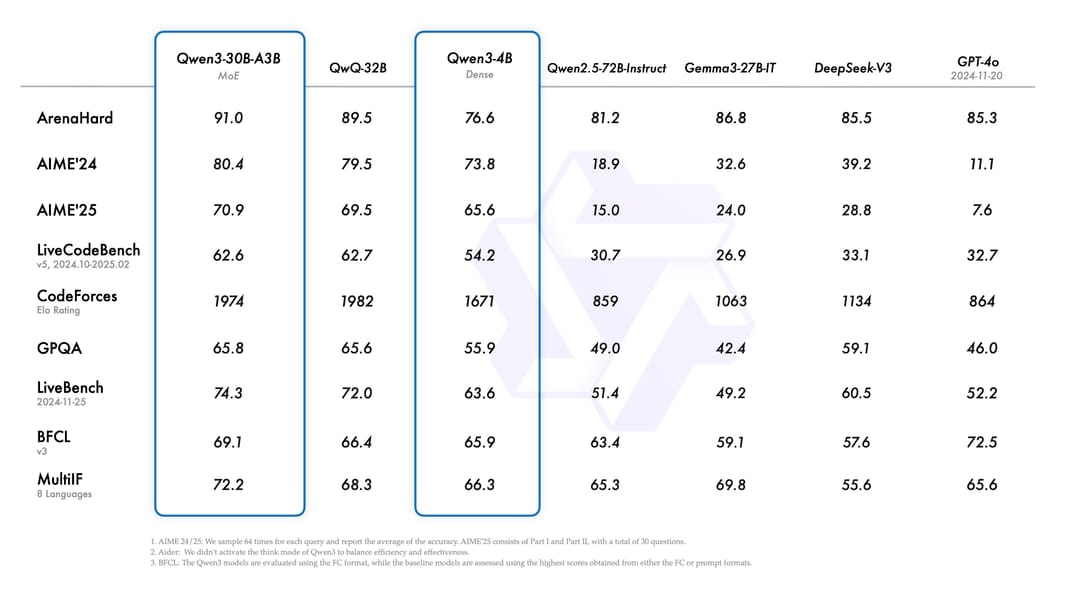
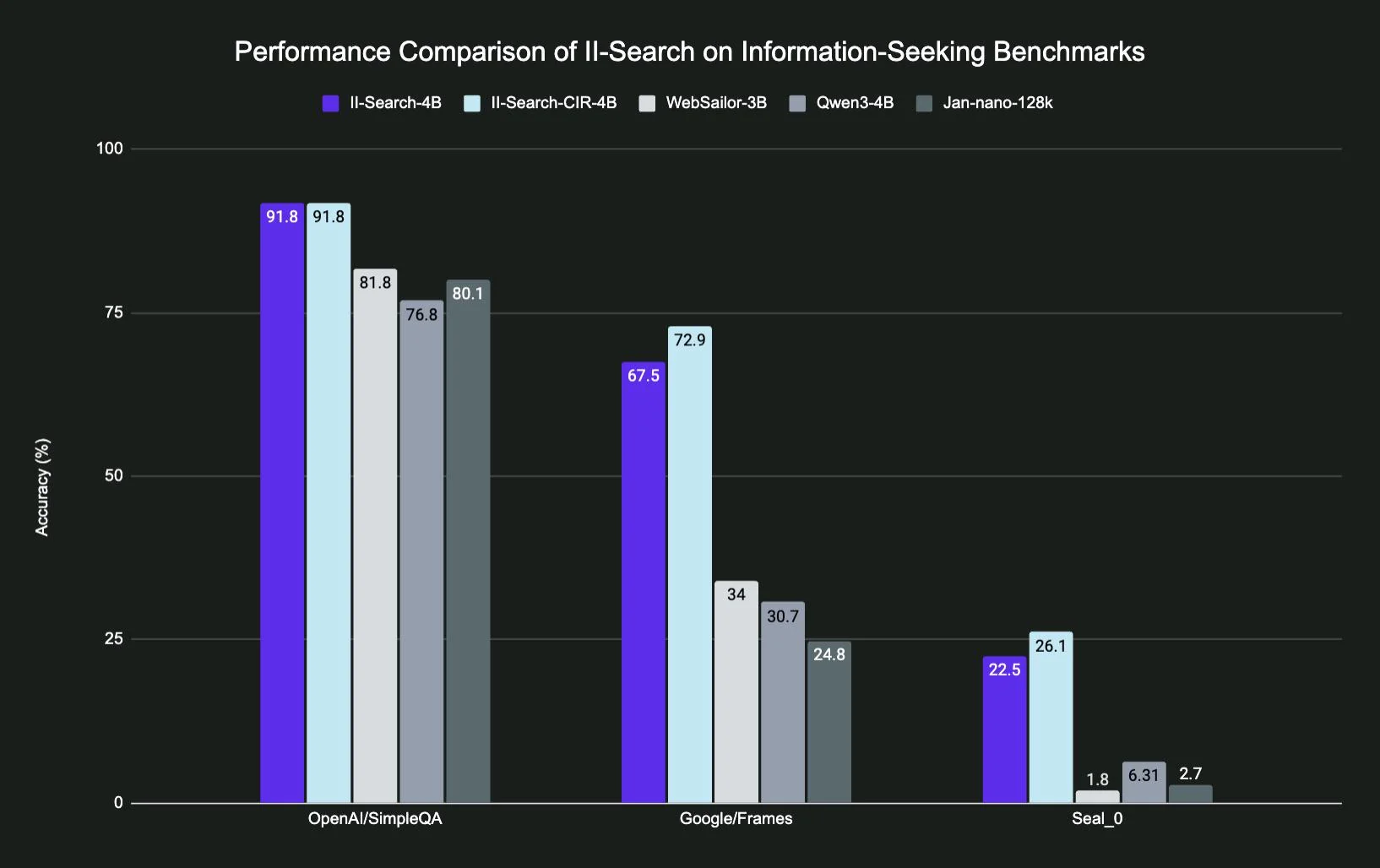
Okay so. Picture this. It’s August 2025, I’m drowning in API costs from o3, my ideas’s runway is… let’s not talk about it… and I stumble across this random Hugging Face model called II-Search-4B. Four billion parameters. FOUR. In an era where everyone’s flexing their 405B models like it’s a #### measuring contest. My first thought? “This is gonna s*ck.” My second thought, three weeks later? “Holy crap this actually works.” ...