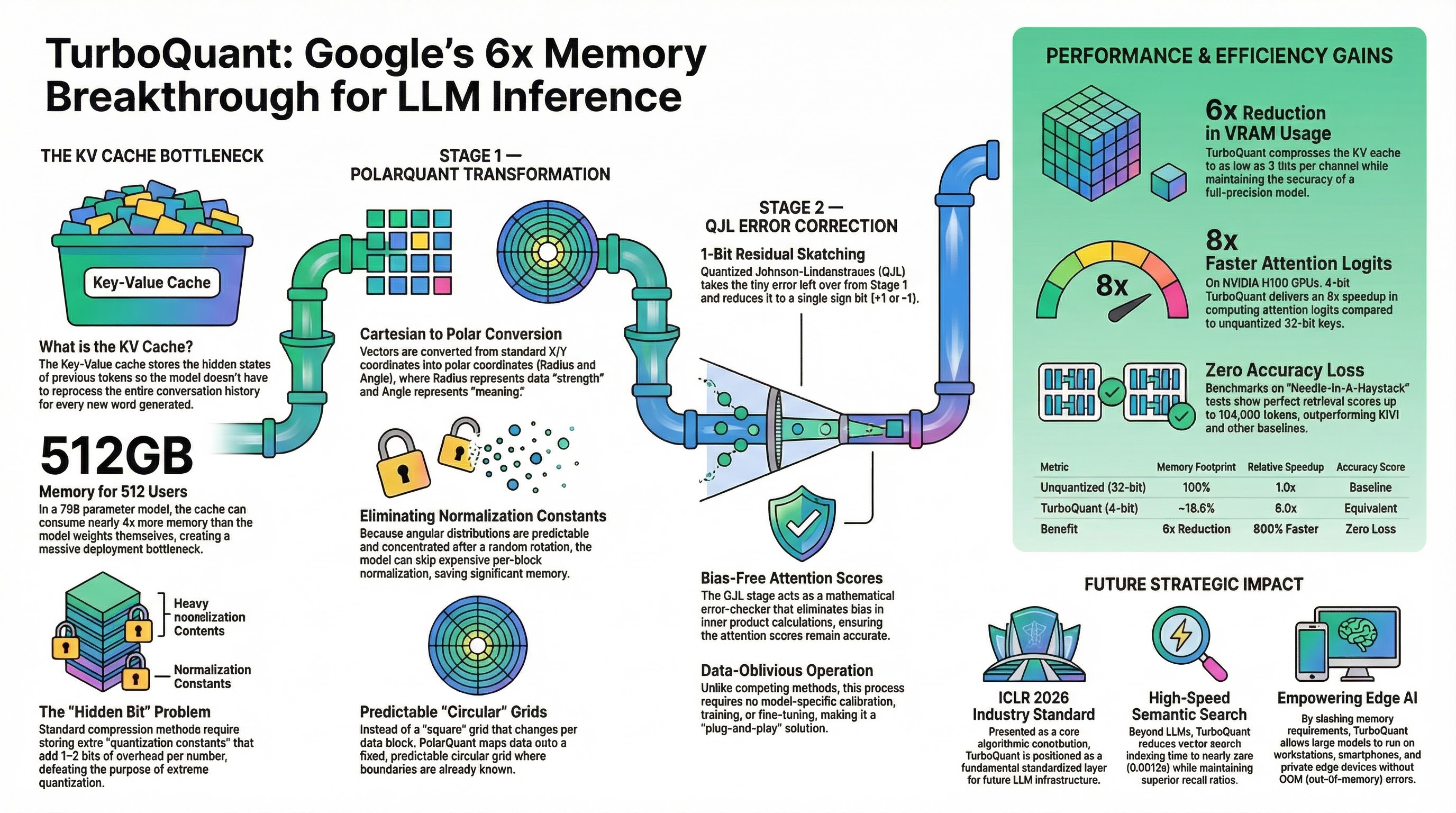
TurboQuant Under the Hood: Google's 3-Bit Attack on the LLM Memory Wall
Most AI efficiency launches are either smaller weights, benchmark theater, or a kernel trick dressed up as a new paradigm. TurboQuant is more interesting than that. On March 24, 2026, Google Research published TurboQuant as a practical compression stack for KV caches and vector search. The public claim was blunt: at least 6x KV-cache reduction, up to 8x attention-logit speedup on H100, and no training or fine-tuning required. Underneath the marketing, the real contribution is cleaner and more important: Google found a way to make extreme low-bit vector quantization behave like a systems primitive instead of a fragile research demo. S1 ...