Reading time: ~24 min | Audience: staff engineers, AI architects, platform leads, senior ICs inheriting a slow conversational system | Primary goal: stop treating a 10 to 13 second LLM workflow like a prompt problem when it is really a systems problem
Preface: Voice Did Not Create the Problem
Here is the version of this story that gets told too often:
“The text bot was fine. Then voice arrived. Now latency matters.”
That is a comforting story because it suggests the architecture was basically sound and only needs a few voice-specific upgrades.
Most of the time, it is false.
If your support assistant takes 10 to 13 seconds to classify a user message, extract facts, look up the right workflow, and draft the next action, the system was already broken. Voice did not create the bug. Voice merely removed your ability to hide it.
That is the real lesson from one recent architecture review I worked through:
- the system had a clean-looking DAG;
- nodes inside each group ran in parallel;
- the product still “worked” in text;
- one trace still took roughly 13 seconds end to end;
- one supposedly parallel stage spiked to about 7.6 seconds;
- the exact same logical task could take closer to 1.7 seconds on other runs.
That last point is the giveaway.
When the same task swings that wildly, your first suspect should not be prompt phrasing. It should be the path the request took through the system.
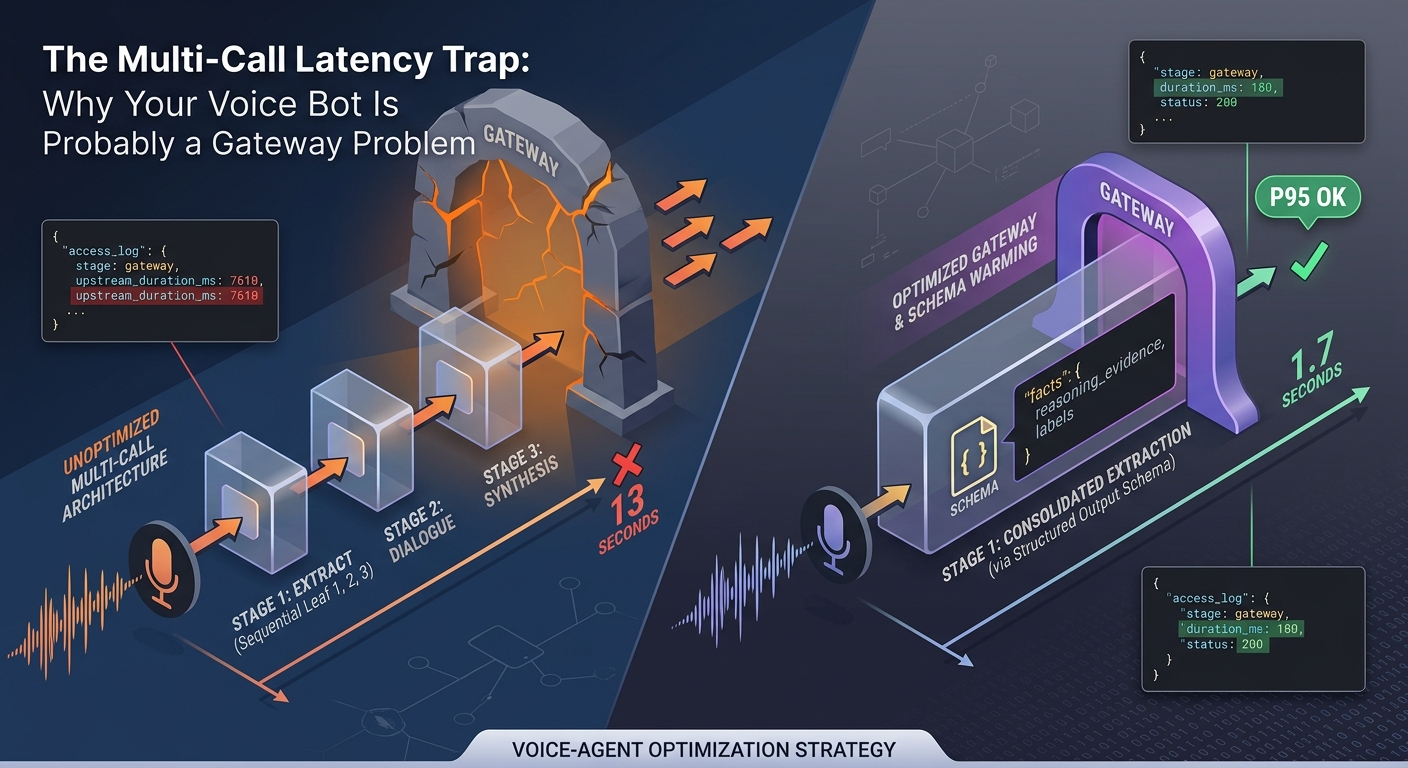
The Real Failure Mode
The architecture under discussion looked roughly like this:
flowchart LR
U["User turn"] --> G1
subgraph G1["Stage 1: extraction and classification"]
I1["Intent"]
I2["Product family"]
I3["Sentiment"]
I4["Facts"]
end
G1 --> G2
subgraph G2["Stage 2: dialogue and context"]
S1["Dialogue state"]
S2["Session context"]
end
G2 --> G3
subgraph G3["Stage 3: enrichment and response prep"]
E1["Knowledge selection"]
E2["Case mapping"]
E3["Response shaping"]
end
G3 --> B["Backend checks and policy"]
B --> R["Reply"]That shape is common because it reflects how teams build software:
- one extraction node gets added for sentiment;
- another gets added for product family;
- another gets added for route selection;
- another gets added because a downstream workflow wants a cleaner schema;
- eventually the graph looks disciplined, but the turn budget is dead.
The user does not experience “parallelism inside each stage.”
The user experiences the slowest leaf in each stage, plus every serial barrier between them:
end_to_end_turn
~= max(stage_1_calls)
+ max(stage_2_calls)
+ max(stage_3_calls)
+ proxy_or_gateway_time
+ backend_time
+ model_time
+ speech_io
So yes, multi-call orchestration has a critical-path problem. But that is only half the story.
The other half is uglier:
if one leaf takes 1.7 seconds in one run and 7.6 seconds in another, there is a decent chance your gateway, proxy, or routing layer is eating the difference.
Step 0: Rule Out the Enterprise Proxy Trap
This is the part too many AI architecture posts skip because it sounds less glamorous than agents and prompting.
It is also the part that usually saves the most time.
Many enterprise LLM systems do not call a model provider directly. They pass through some combination of:
- enterprise API gateways
- zero-trust proxies
- self-hosted gateways
- internal “AI foundation” routing layers
- regional traffic managers
- rate-limit enforcement services
- compliance filters
These layers are often operationally necessary. They are also frequent sources of latency variance.
Microsoft’s own GenAI gateway reference architecture notes that when a cloud-based API Management gateway fronts on-premises services, the gateway can increase latency because the Azure network processes every request before policies are applied and proper network setup becomes critical. The same guidance also notes that aggressive payload capture and sampling can hurt throughput and add latency. S6
That means a voice-readiness review should begin with a brutally simple question:
Are you sure the model is slow, or is the network path slow?
Before you change prompts, models, or graph topology, prove where the missing seconds went.
What to log first
If the request crosses a gateway or reverse proxy, capture these fields before you touch the LLM:
request_idtraceparent- gateway arrival timestamp
- upstream target host or region
- total gateway duration
- upstream service duration
- response code
- retry count
- response flags or timeout flags
- model request start and end timestamps
- tool/backend request start and end timestamps
Envoy’s access-log model is a good mental template here because it is built around explicit timing and request metadata fields, not vibes. S7 Even if you are not using Envoy, the principle holds: the first artifact you need is not a fancy span tree. It is a path-level timing record that lets you separate gateway time from upstream time.
A practical diagnostic sequence
If the same logical node sometimes runs in 1.7 seconds and sometimes in 7.6 seconds, walk the path in this order:
- Gateway or reverse proxy duration.
- Upstream connect and queue time.
- Provider round-trip time.
- Application-side serialization and JSON handling.
- Only then model prompt and token generation.
That order matters because prompt optimization does not fix a cold, overloaded, or badly routed gateway.
The Observability Paradox: You Need Traces, but You Are Not Allowed to Have Them
This is the other uncomfortable reality from real enterprise systems: production debugging often happens under restrictions.
Sometimes InfoSec or platform engineering will not allow a full tracing SDK in production. Sometimes the concern is data residency. Sometimes it is payload logging. Sometimes it is performance overhead. Sometimes it is simply bureaucracy.
That does not mean you get to say, “No tracing, therefore no diagnosis.”
It means you need a lower-overhead debugging strategy.
OpenTelemetry’s own performance guidance is explicit on the point: telemetry should not block the end-user application by default, should not consume unbounded memory, and should provide a trade-off between dropping information and avoiding application blocking under load. S9
So if a heavy tracing vendor is politically blocked, do this instead.
Use native structured logs as your first production debugger
Start with boring JSON logs on every request boundary:
{
"ts": "2026-03-23T18:41:12.442Z",
"request_id": "7f3d6f2d",
"traceparent": "00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01",
"stage": "gateway",
"target": "llm-router-eu-west",
"duration_ms": 6123,
"upstream_duration_ms": 5870,
"status": 200,
"retry_count": 1,
"timeout_flag": false
}
Then emit corresponding logs from:
- ingress
- gateway
- LLM adapter
- retrieval layer
- policy or business-rule service
- final response assembler
Use the same request identifier and, ideally, the same W3C trace context across layers so you can stitch a request together after the fact. S8
Operational warning: do not assume your LLM SDK propagates that trace context automatically just because your application has one. In practice you often need to inject traceparent explicitly through the SDK’s request options or underlying HTTP client transport, otherwise the gateway and the model call show up as unrelated requests and your timing story falls apart. OpenAI’s own Python SDK exposes this kind of customization through the underlying httpx client for exactly that reason. S14
This is not as pleasant as full distributed tracing. But it is often enough to answer the question that matters:
Did the six extra seconds happen before the model, inside the model call, or after it?
Why this works better than “just enable more tracing”
Because in low-latency systems, the first goal is attribution, not perfect visualization.
You do not need a gorgeous flame graph to discover that:
- one gateway region is overloaded;
- one upstream path retries more often;
- one backend has periodic cold-start behavior;
- one model adapter serializes enormous payloads;
- one stage barrier waits on a call that should never have been in the critical path.
13 Seconds Was Already Bad for Text
Another correction worth making: 13 seconds is not “fine for text.”
It is just easier to ignore in text.
A text chatbot with 10 to 13 second turn latency already has:
- poor perceived responsiveness,
- higher abandonment risk,
- weaker conversation flow,
- less room for backend failures,
- worse operator confidence during incidents.
Voice does not introduce a new quality bar out of nowhere. It forces the team to confront the quality bar they were already failing.
Human turn-taking research shows how tight conversational expectations really are: across languages, response transitions cluster most densely between 0 and 200 milliseconds, and the average gaps remain surprisingly narrow. S10 WebRTC guidance translates that into engineering language: once lag grows, overlap and confusion become more likely. S11
No production support bot needs to hit 200 milliseconds wall-clock for the full answer. But if your first meaningful response starts after several seconds, your system is no longer participating in a conversation. It is periodically dropping announcements into one.
The Right Optimization Order
Once you stop treating this as a pure “model is slow” problem, the sequence becomes clearer.
1. Prove whether the missing seconds are in the gateway
Do this first.
Not second. Not after an eval run. Not after prompt cleanup.
If the proxy path is unstable, fix that instability or at least measure it accurately before you rewrite anything else.
2. Run the model swap experiment offline
This part from the original discussion was directionally correct.
If the system already has:
- a Golden Dataset
- an evaluation harness
- stable test cases
then swapping narrow classification and extraction nodes to a smaller, faster sub-model is a sensible next experiment.
The reason is simple:
- it is cheaper than rewriting the graph;
- it is measurable;
- it often produces immediate latency gains on narrow tasks;
- it tells you whether the model is actually the bottleneck at all.
Recent official guidance makes the same general point from a different angle: reduce request count, choose faster models where appropriate, and do not default to high-capability models for tasks that do not require them. S2
In practice that usually means keeping the frontier model for synthesis, exception handling, or policy-heavy judgment, while routing narrow tasks like sentiment, product-family extraction, or lightweight classification to sub-models such as gpt-4o-mini, gpt-4.1-mini, or Haiku-class equivalents. That is not a novel trick anymore. It is the standard latency-and-cost playbook for production AI systems in 2024-2026.
What you should not do is romanticize this step. It is not a masterstroke of architectural discipline. It is simply the cheapest controlled experiment available.
3. Collapse obvious extraction fan-out into one structured-output call
This is where the original article needed to be much more concrete.
If stage 1 contains four parallel calls that all read the same user turn and all emit compact fields, stop pretending they are independent microservices. In many systems they are just four ways of paying network overhead four times.
This is the exact class of work where structured outputs help:
- intent
- product family
- sentiment
- fact extraction
- next likely backend checks
Official OpenAI guidance for latency says to make fewer requests. The structured-output route is often the most practical way to do that while keeping the result easy to parse. S2 S3
There is an important trade-off here, and senior engineers will notice it immediately: four separate extraction calls can generate tokens concurrently, while one merged structured-output call generates its fields sequentially inside a single completion. So this is not a universal win. It is the right trade in the specific environment described here because the dominant risk is not model decoding speed. It is network variance across multiple enterprise hops. If the gateway has even a small chance of turning one branch into a six-second outlier, collapsing four requests into one reliable hop is usually better math than preserving parallel generation and paying fan-out risk four times.
There is also a deployment trap: the first request with a new strict structured-output schema pays an extra preprocessing cost while OpenAI turns that schema into a cached grammar artifact. Official guidance says typical schemas take under 10 seconds on the first request, while more complex schemas can take up to a minute. S15 So do not judge this pattern from a cold first call in staging. Warm the schema on deploy, then measure steady-state latency.
A practical single-call schema looks like this:
{
"facts": {
"symptom": "device stopped charging",
"purchase_signal": "mentions warranty",
"serial_number_present": false
},
"sentiment": "frustrated",
"product_family": "electric_toothbrush",
"intent": "product_issue",
"next_checks": [
"knowledge_lookup",
"registration_check"
]
}
That field order is deliberate. This is an engineering heuristic rather than an API guarantee, but when generation is sequential you usually want evidence-bearing fields first and conclusive labels later. In other words: extract the facts, then label the turn. Even if your downstream parser treats JSON object order as irrelevant, the model still emits tokens one step at a time.
And the prompt should be equally boring:
You are an extraction component inside a customer support orchestrator.
Return one JSON object only.
Do not explain your reasoning.
Extract:
- facts.symptom
- facts.purchase_signal
- facts.serial_number_present
- sentiment
- product_family
- intent
- next_checks
If a field is unknown, return null.
That is a real trench-level change. It is not theoretical. It directly reduces:
- round trips,
- gateway exposure,
- serialization overhead,
- fan-out tail risk.
4. Pull deterministic business logic out of the LLM path
This advice stays, but it needs to be framed realistically.
No, you are not rewriting the whole enterprise refund and warranty platform in three days.
What you can do quickly is identify the worst offenders:
- eligibility checks that already exist in a typed service;
- routing thresholds that could be table-driven;
- policy decisions that should come from code or rules, not model prose;
- registration lookups that belong in a backend call, not a prompt.
You do not need full architectural purity to win latency back. You need to stop wasting model time on questions the model should never have been asked.
5. Only after that, attack stage barriers
This is where speculative retrieval, incremental reasoning, and streaming orchestration become relevant.
But they are not the baseline recovery plan for a team that still cannot prove whether its gateway is swallowing six seconds.
They are second-order optimizations.
Useful ones, sometimes necessary ones, but second-order all the same.
A Realistic Recovery Plan for the Trenches
If I were dropped into this problem with a frustrated team and an upcoming voice milestone, I would run the recovery like this.
Phase 1: 48-hour forensic pass
Goal: attribute the latency before changing behavior.
- Add structured request logs at gateway, app, LLM adapter, and tool boundaries.
- Propagate
request_idandtraceparentacross every hop. S8 - Capture gateway duration, upstream duration, retry count, and target host.
- Build a quick table of median, P95, and max by stage and by upstream path.
Deliverable:
- one page that shows where the worst-case requests actually spend time.
Phase 2: one controlled model benchmark
Goal: find out whether smaller models help enough on narrow nodes to matter.
- Keep the graph unchanged.
- Swap only the extraction/classification nodes.
- Run against the Golden Dataset.
- Measure quality, median latency, and tail latency.
Deliverable:
- a decision table, not a demo.
Phase 3: one request-consolidation change
Goal: delete unnecessary round trips.
- Combine intent, product-family, sentiment, and fact extraction into one structured-output call.
- Keep downstream contracts stable by mapping the new schema onto the existing graph.
- Re-run the same eval set.
Deliverable:
- one merged extractor in staging with hard numbers.
Phase 4: one business-logic extraction
Goal: shorten the critical path by removing a deterministic branch.
- choose exactly one backend decision that does not belong in the model path;
- move it behind typed code or an existing service;
- compare end-to-end latency before and after.
Deliverable:
- one critical-path branch removed from the model runtime.
Phase 5: honest voice gating
Goal: decide whether the system is actually ready for voice.
Measure all of these with speech in the loop:
- turn-end detection to first token
- turn-end detection to first audible response
- full response completion
- interruption handling
- cancellation waste
- P95 under realistic concurrency
Also inspect your voice activity detection settings before you blame the model. OpenAI’s Realtime guidance is explicit that server_vad endpointing depends on parameters such as threshold, prefix_padding_ms, and especially silence_duration_ms, where shorter silence windows detect turns more quickly. S13 In real systems it is common to lose 500 to 800 milliseconds before the model even starts because the endpointing layer is still waiting to decide whether the user is done speaking.
If you are using OpenAI’s Realtime API, also evaluate semantic_vad instead of assuming server_vad is good enough. semantic_vad uses a classifier over the spoken content to decide whether the user’s thought is complete, which helps it avoid treating every hesitation as a hard stop or every pause as wasted silence. S13 It can claw back noticeable dead air, but you still need to test interruption behavior and false turn endings on real conversation data.
If you only test text plus TTS at the end, you are not validating voice readiness. You are validating a lab fantasy.
What Comes After the Basics
Only once the system is no longer obviously bottlenecked by gateway variance, fan-out waste, and missing observability should you move into more advanced patterns.
That includes:
- speculative retrieval,
- branch cancellation,
- incremental reasoning on partial audio,
- separating a fast “speaker” path from a slower “thinker” path,
- semantic triggering instead of waiting for fully settled turns.
Recent work like LTS-VoiceAgent is interesting precisely because it tries to reduce the strict serial dependence of listen -> think -> speak pipelines and improve the accuracy-latency trade-off for streaming voice interaction. S12
That is valuable research.
It is also not where a struggling team should start if:
- their proxy path is unstable,
- their production observability is restricted,
- their extraction stage is still fan-out-heavy,
- their graph still hides deterministic work inside LLM nodes.
Advanced streaming architectures reward strong fundamentals. They do not replace them.
The Lesson Staff Engineers Usually Learn the Hard Way
The most expensive mistake in this category of systems is solving the wrong layer first.
If you mistake gateway variance for model slowness, you will waste weeks on prompts. If you mistake missing observability for missing cleverness, you will build an un-debuggable system. If you mistake fan-out architecture for rigor, you will keep paying tail-latency tax on every turn.
So the practical rule is:
Before you optimize the LLM, prove the network is not swallowing the budget.
Then:
- reduce request count,
- move cheap tasks to small models,
- remove deterministic logic from the model path,
- measure again,
- only then reach for advanced voice patterns.
That is not as exciting as writing a manifesto about agentic orchestration.
But it is how you ship a voice system that does not humiliate itself the first time a user says hello.
Source Mapping
- S1: The Tail at Scale (tail latency amplification in fan-out systems) - https://www.barroso.org/publications/TheTailAtScale.pdf
- S2: OpenAI latency optimization guide (fewer requests, parallelize, speculative execution, do not default to an LLM) - https://platform.openai.com/docs/guides/latency-optimization
- S3: OpenAI prompt engineering guidance including structured outputs - https://platform.openai.com/docs/guides/prompt-engineering
- S6: Microsoft GenAI gateway reference architecture with APIM (gateway latency and monitoring trade-offs) - https://learn.microsoft.com/en-us/ai/playbook/solutions/genai-gateway/reference-architectures/apim-based
- S7: Envoy Gateway access log design and Envoy access-log references - https://gateway.envoyproxy.io/contributions/design/proxy-accesslog/
- S8: W3C Trace Context recommendation - https://www.w3.org/TR/trace-context/
- S9: OpenTelemetry performance and blocking guidance - https://opentelemetry.io/docs/specs/otel/performance/
- S10: Stivers et al., Universals and cultural variation in turn-taking in conversation - https://pubmed.ncbi.nlm.nih.gov/19553212/
- S11: MDN WebRTC RTP introduction (why low latency matters in real-time communication) - https://developer.mozilla.org/en-US/docs/Web/API/WebRTC_API/Intro_to_RTP
- S12: LTS-VoiceAgent: A Listen-Think-Speak Framework for Efficient Streaming Voice Interaction via Semantic Triggering and Incremental Reasoning - https://arxiv.org/abs/2601.19952
- S13: OpenAI Realtime VAD guide (
server_vad,semantic_vad,silence_duration_ms) - https://platform.openai.com/docs/guides/realtime-vad - S14: OpenAI Python SDK documentation on configuring the underlying HTTP client - https://github.com/openai/openai-python#configuring-the-http-client
- S15: OpenAI Structured Outputs announcement (CFG preprocessing, first-request schema latency) - https://openai.com/index/introducing-structured-outputs-in-the-api/