Most AI efficiency launches are either smaller weights, benchmark theater, or a kernel trick dressed up as a new paradigm. TurboQuant is more interesting than that.
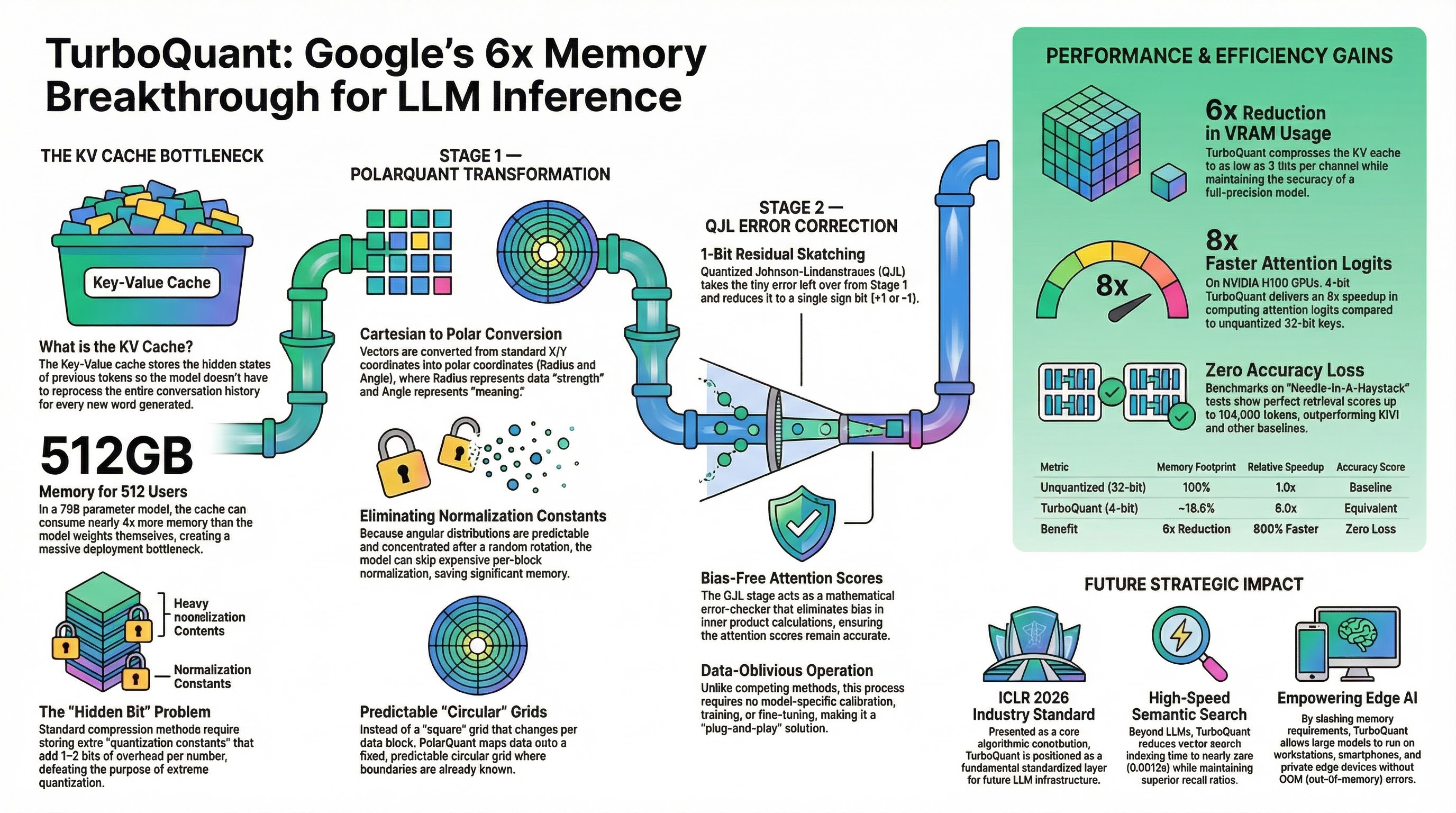
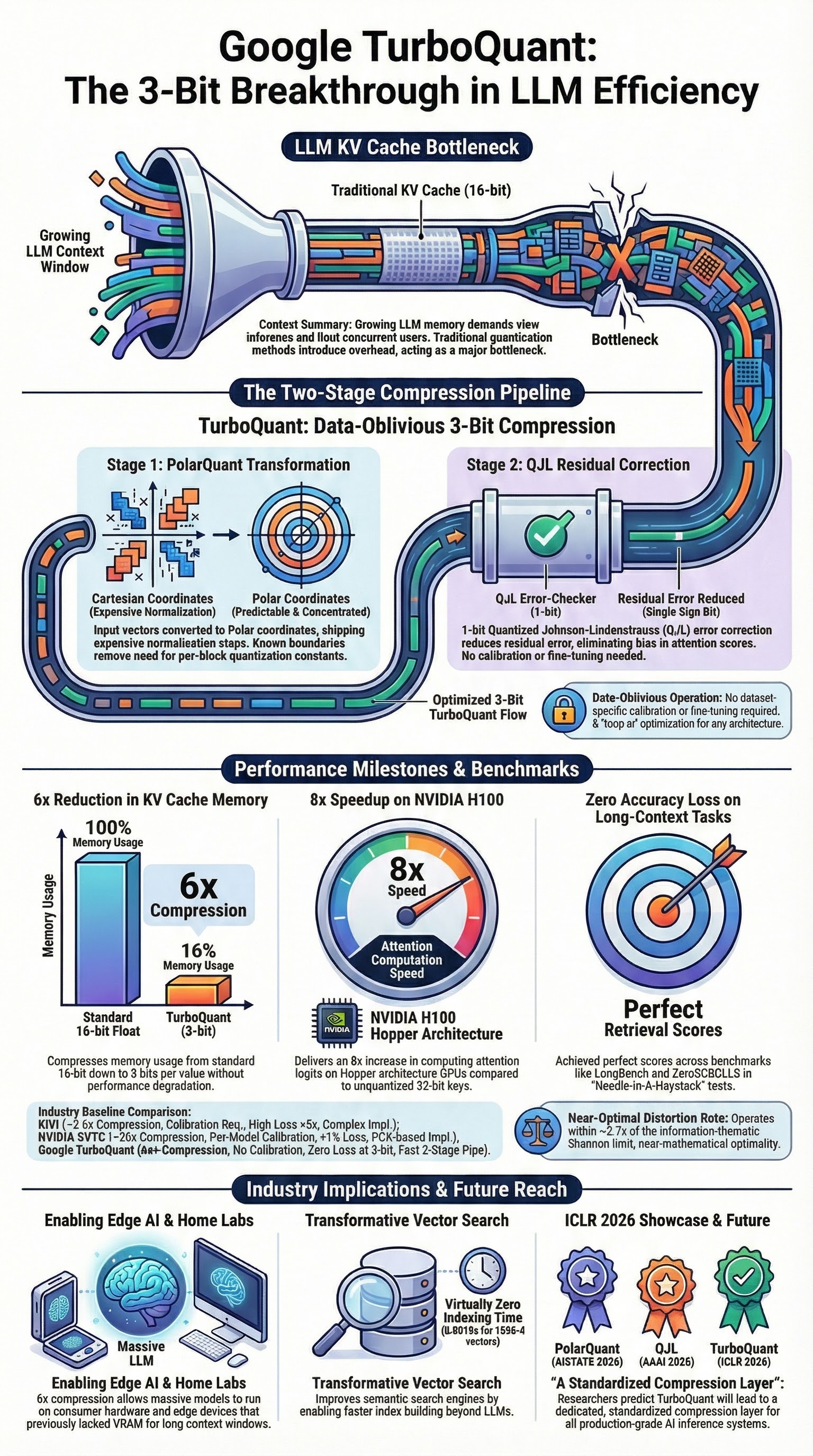
On March 24, 2026, Google Research published TurboQuant as a practical compression stack for KV caches and vector search. The public claim was blunt: at least 6x KV-cache reduction, up to 8x attention-logit speedup on H100, and no training or fine-tuning required. Underneath the marketing, the real contribution is cleaner and more important: Google found a way to make extreme low-bit vector quantization behave like a systems primitive instead of a fragile research demo. S1
The key point is not “3-bit AI.” The key point is that TurboQuant attacks the decode-time memory wall where modern LLM serving actually hurts. It does that by combining three ideas:
- random rotation to regularize coordinate statistics;
- scalar quantization matched to those post-rotation statistics;
- a 1-bit residual correction path so inner products stay unbiased.
That stack matters because the KV cache is often the thing that scales linearly with context length, competes directly with weights for memory, and turns expensive accelerators into DRAM wait states. S1 S2 S4
Reality Check: What Google Actually Claimed
The current public record is better than the hype cycle, but only if you read the papers instead of the reposts.
- Google Research’s blog post, published on March 24, 2026, says TurboQuant reduces KV memory by at least 6x, quantizes KV cache to 3 bits, and can deliver up to 8x faster attention-logit computation on H100 for a 4-bit configuration relative to 32-bit unquantized keys. S1
- The ICLR 2026 TurboQuant paper is more precise than the blog: it claims “absolute quality neutrality” at 3.5 bits per channel and marginal quality degradation at 2.5 bits per channel for KV-cache quantization, plus stronger recall and near-zero indexing time in vector-search experiments. S2
- PolarQuant, the 2025 precursor, showed that random preconditioning plus polar-coordinate quantization could compress KV caches by more than 4.2x while removing explicit normalization overhead. S3
- QJL, introduced in 2024, showed that a 1-bit Quantized Johnson-Lindenstrauss sketch could quantize KV cache with zero quantization-constant overhead, achieve more than fivefold memory reduction, and still preserve accuracy. S4
That gives us the right interpretation:
- TurboQuant is not “all quantization solved.”
- TurboQuant is not weight quantization.
- TurboQuant is not proof that every reasoning workload is safe at 3 bits.
- TurboQuant is a serious advance in online, data-oblivious, low-overhead vector quantization for KV caches and vector search. S2 S3 S4
Why KV Cache Is the Right Place to Fight
If you care about long-context inference, the KV cache is where memory economics stop being abstract.
For autoregressive decoding, the cache grows with every generated token. A useful mental model is:
KV cache bytes ≈ 2 × num_layers × num_kv_heads × head_dim × sequence_length × bytes_per_value
That growth is painful for two separate reasons.
First, there is the capacity problem. Long contexts can push cache size into the same order of magnitude as model weights. Second, there is the bandwidth problem. During decode, the machine keeps pulling keys and values through the memory hierarchy for attention, which means the bottleneck shifts from arithmetic to movement. The TurboQuant paper explicitly frames inference latency as a communication problem between HBM and SRAM, not a shortage of FLOPs. S1 S2
That is why this work matters more than another slightly better W4 weight packer. Weight quantization helps you fit the model. KV-cache quantization helps you keep serving it under long contexts without drowning in memory traffic.
There is also a subtle but important accounting point here. If you naively compare 16 bits -> 3 bits, you get a theoretical 5.33x shrink. Google reports at least 6x in public results because older KV quantizers are not really as low-bit as their headline number suggests. They pay a hidden metadata tax for per-block scales and zero-points. QJL and PolarQuant matter because they target that overhead directly. S1 S3 S4
Failure mode: If your workload is short-context, prefill-heavy, or dominated by weight reads rather than KV traffic, TurboQuant will not look magical.
Mitigation: Profile sequence-length percentiles, decode share, and cache bytes per generated token before you adopt any low-bit KV scheme.
How the Pipeline Actually Works
The cleanest way to understand TurboQuant is to ignore the slogans and follow the data path.
flowchart LR A["FP16/BF16 KV vector"] --> B["Random rotation"] B --> C["Coordinate statistics become predictable"] C --> D["Lloyd-Max scalar quantization"] D --> E["Low-bit base representation"] B --> F["Residual after dequantization"] F --> G["1-bit QJL on residual"] E --> H["Packed KV cache"] G --> H H --> I["Unbiased inner-product estimation during attention"]
1. Random rotation is the trick that makes the rest possible
TurboQuant randomly rotates the input vectors before quantization. In the paper, this induces coordinate distributions that follow a concentrated Beta distribution and become nearly independent in high dimensions. That matters because it turns ugly, model-specific coordinate structure into something scalar quantizers can handle efficiently with precomputed codebooks. S2
This is the real unlock. Without that rotation, per-coordinate quantization is much more vulnerable to outliers, privileged channels, and layer-specific pathologies.
2. Scalar quantization is only optimal because the distribution changed first
After rotation, TurboQuant uses Lloyd-Max scalar quantizers per coordinate. That sounds almost disappointingly classical, which is exactly the point. Instead of learning a codebook per dataset or calibrating per tensor, TurboQuant leans on predictable post-rotation statistics and precomputes optimal scalar codebooks for practical bit-widths. S2
This is why the system is online-friendly. It does not need a calibration dataset for each new workload. It does not need a reconstruction pass. It does not need heavy preprocessing like many offline quantization schemes. S2
3. QJL exists because low MSE is not enough
A low-MSE quantizer does not automatically preserve the thing attention actually cares about: inner products.
TurboQuant fixes that with a second stage. After the main quantizer reconstructs an approximation, the residual is passed through a 1-bit Quantized JL transform. That gives the system an unbiased inner-product estimator with low distortion, instead of a merely good reconstruction error. This is the part many summaries flatten into “plus one bit.” It is more precise to say that TurboQuant uses a tiny residual sketch to repair the bias that MSE-optimal quantizers introduce into dot-product estimation. S2 S4
4. Where PolarQuant fits
Google’s own blog positions TurboQuant alongside, and partly on top of, PolarQuant and QJL. PolarQuant showed that random preconditioning plus polar transformation lets you skip explicit normalization, which removes the scale-and-zero-point overhead that bloats prior low-bit methods. TurboQuant then pushes the idea toward a broader vector-quantization framework with near-optimal distortion guarantees and a residual QJL correction stage. S1 S3
If you want the blunt version:
- PolarQuant proved the overhead problem could be attacked structurally. S3
- QJL proved 1-bit residual sketches could preserve inner products without metadata. S4
- TurboQuant fused those instincts into a more general, more practical online quantizer. S1 S2
Failure mode: If you remove the residual correction path and keep only the low-MSE quantizer, your reconstruction error can still look fine while attention scores drift.
Mitigation: Evaluate downstream attention behavior, retrieval recall, and sequence-task accuracy, not just reconstruction metrics.
What the Benchmarks Actually Say
The benchmark story is good. It is not infinite. That distinction matters.
Needle-in-a-Haystack: the strongest public evidence
In the ICLR paper, TurboQuant was evaluated on Llama-3.1-8B-Instruct over document lengths from 4k to 104k tokens. Under a 0.25 memory ratio, TurboQuant achieved a 0.997 Needle-in-a-Haystack score, matching the 0.997 full-precision baseline and beating KIVI’s 0.981, while PolarQuant reached 0.995. S2
That is the best evidence for the headline claim because it is a direct long-context retrieval test under aggressive compression, not an abstract microbenchmark. S2
LongBench: good news, with nuance
On LongBench-V1 for Llama-3.1-8B-Instruct, the paper reports:
| Method | KV Size (bits/channel) | Average Score |
|---|---|---|
| Full Cache | 16 | 50.06 |
| KIVI | 3 | 48.50 |
| PolarQuant | 3.9 | 49.78 |
| TurboQuant | 2.5 | 49.74 |
| TurboQuant | 3.5 | 50.06 |
The important line is the last one: 3.5-bit TurboQuant matched the full-cache average exactly at 50.06 on that benchmark mix, while 2.5-bit TurboQuant degraded only slightly to 49.74. That supports the paper’s “quality neutrality at 3.5 bits” claim much better than the vague phrase “zero accuracy loss everywhere.” S2
Speedup: real, but read the fine print
Google’s blog claims up to 8x faster attention-logit computation on H100 with a 4-bit TurboQuant configuration relative to 32-bit unquantized keys. That is meaningful, but it is also a very specific claim:
- it is about attention-logit computation, not necessarily end-to-end user latency;
- it is measured against 32-bit unquantized keys, not the best tuned production alternative;
- and it reflects Google’s implementation context, not your current serving stack by default. S1
Treat this as strong evidence that the method is hardware-relevant, not as a promise that your entire inference path becomes 8x faster.
Vector search may be the more underrated story
The ICLR paper also evaluates TurboQuant on DBpedia Entities with OpenAI text-embedding-3-large embeddings at 1536 and 3072 dimensions, plus GloVe at dimension 200. TurboQuant outperformed Product Quantization and RabitQ on recall@k while cutting indexing time to nearly zero because it avoids heavy data-dependent training passes. S2
That matters because the method is not just a KV-cache trick. It is a general answer to a broader question: how do you compress high-dimensional vectors fast enough to use the compression online? S2
The useful way to read the public TurboQuant story is not “3 bits are magic.” It is that Google has a credible path to low-overhead online vector compression at a bit regime where older methods usually start paying too much metadata tax.
Failure mode: Teams read “zero loss” and stop measuring anything except throughput.
Mitigation: Anchor evaluation on long-context retrieval, task-specific reasoning, and effective memory reduction, not only on synthetic kernel graphs.
Where It Sits Against KIVI, KVQuant, and AWQ
TurboQuant is good, but the comparison set matters.
| Method | Primary Target | What It Does Well | Where It Bites Back |
|---|---|---|---|
| TurboQuant | KV cache, vector search | Data-oblivious online quantization, low metadata overhead, strong long-context results | Newer ecosystem, kernel maturity still matters S1 S2 |
| PolarQuant | KV cache | Removes normalization overhead, strong quality at >4.2x compression | Narrower precursor method, not the full TurboQuant story S3 |
| QJL | KV cache inner products | 1-bit residual sketch, unbiased estimator, >5x memory reduction | Not the whole quantizer on its own S4 |
| KIVI | KV cache | Tuning-free 2-bit asymmetric KV quantization, practical baseline | Still pays overhead and trails TurboQuant on public long-context quality S2 S5 |
| KVQuant | KV cache at extreme context | Reaches 1M context on one A100-80GB and 10M on 8 GPUs, <0.1 perplexity degradation | More system complexity, lower reported speedup than Google’s H100 claim S6 |
| AWQ | Weights | Protects salient weights, widely useful for on-device W4 deployment | Not a direct KV-cache replacement; it solves a different memory problem S7 |
The most common comparison mistake is treating AWQ or GPTQ as direct competitors. They are not. Those methods primarily compress weights. TurboQuant primarily compresses runtime state. In practice, serious deployments will combine both:
- use AWQ or another weight quantizer to fit the model;
- use TurboQuant or another KV strategy to survive long contexts and high concurrency.
KIVI and KVQuant are the closer apples-to-apples comparisons because they also target KV caches. KIVI showed the field that very aggressive KV compression was feasible. KVQuant pushed the frontier on extremely long contexts. TurboQuant’s distinct contribution is that it couples strong public long-context quality with an online, theoretically grounded, low-overhead formulation. S2 S5 S6
Download the comparison matrix used in the research pack
Three Implementation Patterns Worth Shipping
This is the part that matters if you actually run systems.
1. Long-context API serving
If your decode path is memory-bound and your users are pushing 32k+ or 64k+ contexts, TurboQuant belongs in the KV layer first, not as a moonshot refactor of the whole inference stack.
Use this shape:
serving_profile:
weights: awq-int4
kv_cache: turboquant-3.5b
enable_when:
min_context_tokens: 32768
decode_share_percent: 60
fallback_when:
longbench_delta_gt: 1.0
latency_regression_percent_gt: 5
kernel_unavailable: true
Tradeoff: You give up implementation simplicity in exchange for more concurrency and longer usable context on the same hardware.
Failure mode: Teams deploy low-bit KV on every route, including short requests where the compression path adds overhead without paying it back.
Mitigation: Gate by sequence length and decode share, not by model identity alone.
2. On-device or edge assistants
TurboQuant is a better edge story when paired with weight compression, not when used alone. The pattern is:
- weight-quantize the backbone with a mature scheme such as AWQ; S7
- use TurboQuant for the conversation cache so multi-turn interaction does not spill out of local memory; S1 S2
- set a hard power and thermal envelope before rollout.
Minimal deployment contract:
edge_profile:
weights: w4
kv_cache: turboquant-3b
max_context_tokens: 65536
power_budget_watts: 8
rollback_on:
thermal_throttle: true
quality_delta_percent_gt: 2
Tradeoff: You keep privacy and latency local, but the transform and kernel path have to be tuned for your actual SoC, not for a paper baseline.
Failure mode: A low-bit scheme looks great in a short demo, then thermal throttling and unsupported kernels kill the win during sustained generation.
Mitigation: Test sustained decode, not just first-token performance.
3. Vector search and RAG index compression
The least appreciated part of TurboQuant may be the vector-search result. Because the quantizer is online and data-oblivious, it is attractive anywhere you want to compress embeddings without a heavy training stage.
Pseudocode:
# Pseudocode, not a literal library API
index = turboquant_encode(embeddings, bits=4)
scores = turboquant_inner_products(query_embedding, index)
top_k = topk(scores, k=20)
Tradeoff: You trade some implementation novelty for less indexing overhead and higher recall than classic PQ baselines at similar low-bit regimes. S2
Failure mode: People assume the vector-search result automatically transfers to every embedding model and ANN backend.
Mitigation:
Re-run recall and indexing tests on your own embeddings, your own corpus, and your own k.
What Can Go Wrong
The fastest way to misuse TurboQuant is to treat it like a universal compression blessing.
| Risk | Why It Happens | What To Do |
|---|---|---|
| “Zero loss” becomes a religion | Public language compresses benchmark-specific results into a universal claim | Use task suites with pass/fail thresholds for your workloads |
| Kernel speedup does not become user latency win | Attention kernels improve while the rest of the pipeline stays untouched | Measure end-to-end TTFT and decode throughput, not only inner kernels |
| Weight memory still dominates | KV compression cannot solve a backbone that is already too large | Pair KV compression with weight quantization |
| Short-context traffic gets slower | Compression overhead is paid where cache pressure was never the problem | Route TurboQuant only to traffic profiles that need it |
| Quiet quality regressions slip into production | Reconstruction metrics look good while downstream behavior drifts | Track retrieval recall, long-context QA, code completion, and reasoning deltas |
There is one more architectural warning worth stating clearly: TurboQuant is a better fit for runtime-state compression than for replacing weight-quantization strategy outright. If your bottleneck is fitting the model at all, start with weights. If your bottleneck is serving long contexts cheaply, start with the KV cache.
Observability and SLOs
If you cannot explain whether the quantized path is helping, you do not have a rollout. You have a science fair project.
The minimum telemetry contract should include:
kv_cache_bytes_per_tokeneffective_kv_compression_ratiodecode_tokens_per_secondattention_kernel_ms_per_tokenttft_msquality_delta_vs_fp16fallback_rate
I would set the first release gates like this:
| Dimension | Release Gate |
|---|---|
| Memory | Effective KV reduction must exceed 4.5x in the production stack |
| Latency | Decode throughput must improve by at least 20% on the target long-context route |
| Quality | Task-specific accuracy delta must remain within 1% of the control path |
| Stability | Automatic fallback must stay below 5% after warm-up |
Why those gates and not the blog headline?
Because the Google headline is a research and product statement. Your SLOs need to be deployment statements.
Failure mode: Teams prove the math and skip the operator view.
Mitigation: Require a side-by-side dashboard for control vs. TurboQuant before any broad rollout.
A 30-60-90 Day Rollout That Makes Sense
The research pack includes a lot of enterprise theatre around adoption. The useful version is much simpler.
Day 30: establish the control
- Identify the routes where decode is memory-bound.
- Log sequence-length distributions and KV bytes per request.
- Build a golden evaluation set for long-context retrieval, summarization, code, and one reasoning-heavy task.
Checkpoint: If your long-context traffic is small or decode is not the bottleneck, stop here and do weight quantization first.
Day 60: canary 3.5-bit KV compression
- Start with the 3.5-bit setting, because that is where the paper reports benchmark parity. S2
- Restrict rollout to one model and one traffic slice.
- Keep automatic rollback to the control path.
Checkpoint: If memory reduction is real but quality or latency does not move in the right direction, your kernel path is not ready.
Day 90: add workload-aware policy
- Keep 3.5-bit as the production-safe path.
- Treat 2.5-bit as experimental until your own task suite says otherwise. S2
- Pilot vector-search compression separately from serving, because the operational envelope is different.
Checkpoint: Only broaden rollout after you can show effective memory gain, quality parity on your own workloads, and stable fallback behavior.
Bottom Line
TurboQuant matters because it attacks the part of LLM inference that hurts in production: memory movement during decode.
The technical move is elegant. Random rotation makes the coordinate statistics predictable. Lloyd-Max scalar quantization exploits that predictability efficiently. QJL repairs the inner-product bias that a plain MSE quantizer would leave behind. The result is a low-overhead online quantizer that is much closer to a real systems building block than most low-bit research.
The sober version is even better than the hype version:
- the public evidence for long-context quality is strong; S1 S2
- the theoretical grounding is real, not decorative; S2
- the overhead story is a genuine advance over earlier KV quantizers; S3 S4
- and the deployment value is highest exactly where the memory wall is highest.
But none of that means you should cargo-cult it.
If your serving stack is not HBM-bound at decode, TurboQuant is not the first lever. If your model weights still do not fit, TurboQuant is not the first lever. If your quality bar is reasoning-heavy and tightly coupled to downstream business logic, “zero loss” is something you verify, not something you inherit from a blog post.
That is the right way to read TurboQuant in March 2026: not as magic, but as a serious compression primitive that finally respects both the math and the machine.