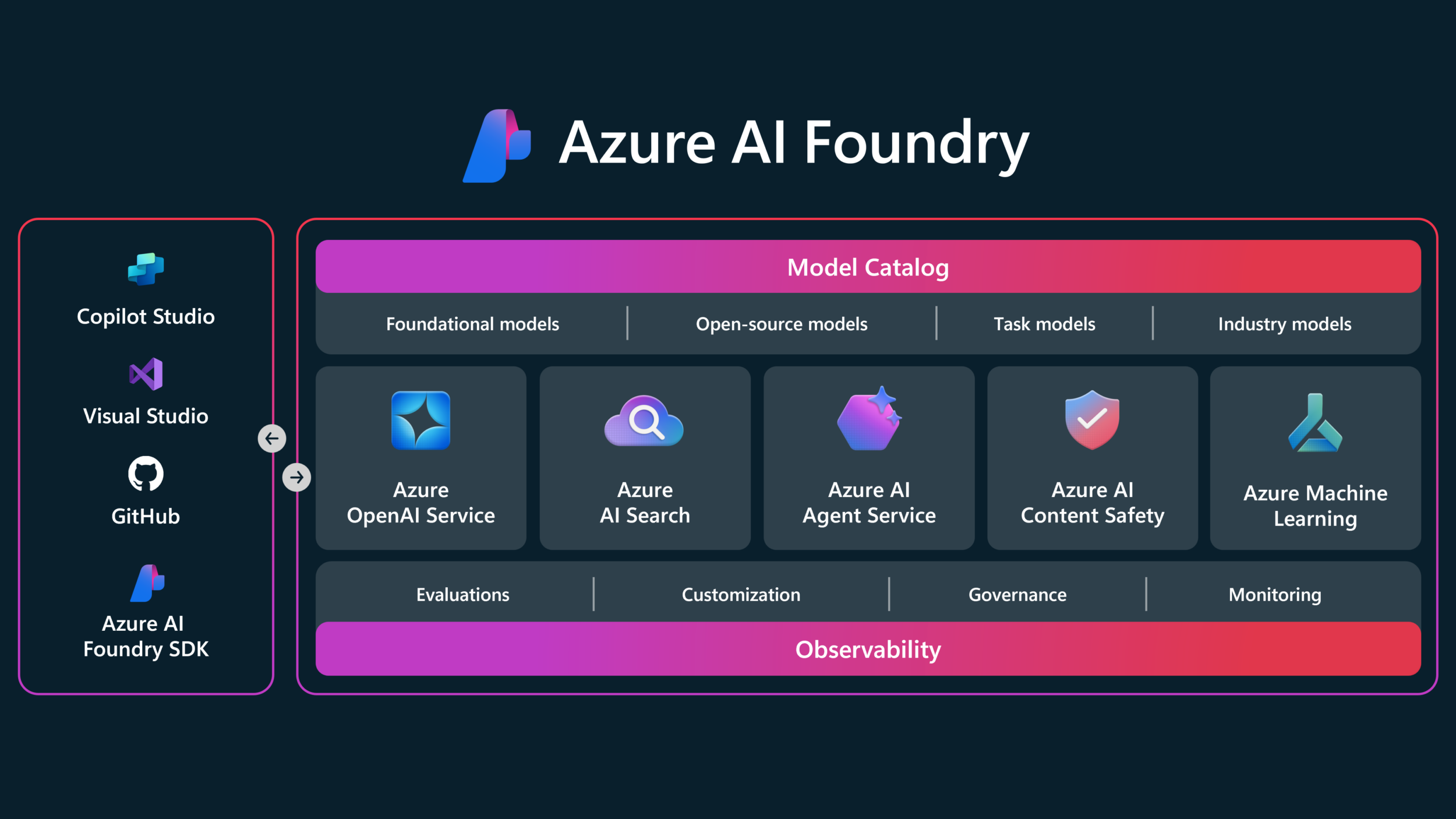
Azure AI Foundry: Building Multi-Agent Systems Without Losing Your Mind (Much)
Hey folks! So, picture this: it’s 3 AM, I’m staring at my fourth attempt to orchestrate multiple AI agents, and my code looks like someone tried to solve the traveling salesman problem with spaghetti. The agents are talking to each other… sometimes. When they feel like it. When Mercury is in retrograde. And then Microsoft drops Azure AI Foundry and promises it’ll solve all my multi-agent orchestration problems. The Problem With Building AI Agents (Or: Why I Started Drinking More Coffee) Let me paint you a picture. You want to build an AI system that actually does something useful. Not just a chatbot that tells you the weather - we’ve all built that demo. I’m talking about real work. Multiple agents, each doing their specialized thing, talking to each other, handling errors, not hallucinating too much. ...